论文笔记 - TextGCD
Textual Knowledge Matters: Cross-Modality Co-Teaching for Generalized Visual Class Discovery
Abstract
在本文中,我们研究了广义类别发现(Generalized Category Discovery,简称 GCD)问题,该问题旨在利用已知类别的标记数据知识,对来自已知和未知类别的未标记数据进行聚类。当前的 GCD 方法仅依赖于视觉线索,然而这忽略了人类在发现新视觉类别时多模态感知特性的认知过程。为了解决这一问题,我们提出了一个两阶段的 TextGCD 框架,通过利用强大的视觉-语言模型来实现多模态 GCD。TextGCD 主要包括基于检索的文本生成(Retrieval-based Text Generation,简称 RTG)阶段和跨模态协同教学(Cross-Modality Co-Teaching,简称 CCT)阶段。首先,RTG 使用来自不同数据集的类别标签和大型语言模型的属性构建视觉词汇表,以检索方式为图像生成描述性文本。其次,CCT 利用文本和视觉模态之间的差异来促进相互学习,从而增强视觉 GCD。此外,我们设计了一种自适应类别对齐策略,以确保模态间的类别感知对齐,以及一种软投票机制来整合多模态线索。在八个数据集上的实验显示,我们的方法在很大程度上优于最先进的方法。值得注意的是,我们的方法在 ImageNet-1 k 和 CUB 上分别以 7.7%和 10.8%的优势超越了最佳竞争者
Introduction
本文提出利用大规模预训练的视觉语言模型(如 CLIP)为广义类别发现(GCD)提供丰富的文本信息。由于 VLMs 依赖于预定义的文本描述符,如类名,来匹配图像,这在处理未标记数据和未知类别时构成挑战。因此,我们提出了 TextGCD 框架,包含检索式文本生成(RTG)和跨模态协同教学(CCT)两个阶段,以结合视觉和文本线索促进 GCD
RTG 阶段从不同数据集和大型语言模型提取类别标签,构建视觉词典,生成描述性文本。然而,整合这些文本信息以增强视觉类别发现是一个挑战。为应对这一挑战,CCT 阶段利用文本和视觉模态的差异促进共同学习。我们设计了跨模态协同教学训练策略,以实现文本和图像模型间的相互学习和增强。在 CCT 之前,引入热身和对齐阶段以确保模态间的类别感知对齐。最后,采用软投票机制整合跨模态协同教学的结果
Contributions
- 我们识别了现有仅依赖视觉线索的广义类别发现(GCD)方法的局限性,并通过基于大规模视觉语言模型(VLMs)的定制化检索式文本生成(RTG)引入额外的文本信息。
- 我们提出了一种文本和视觉模态之间的协同教学策略,以及模态间信息融合方法,以充分利用不同模态在类别发现中的优势。
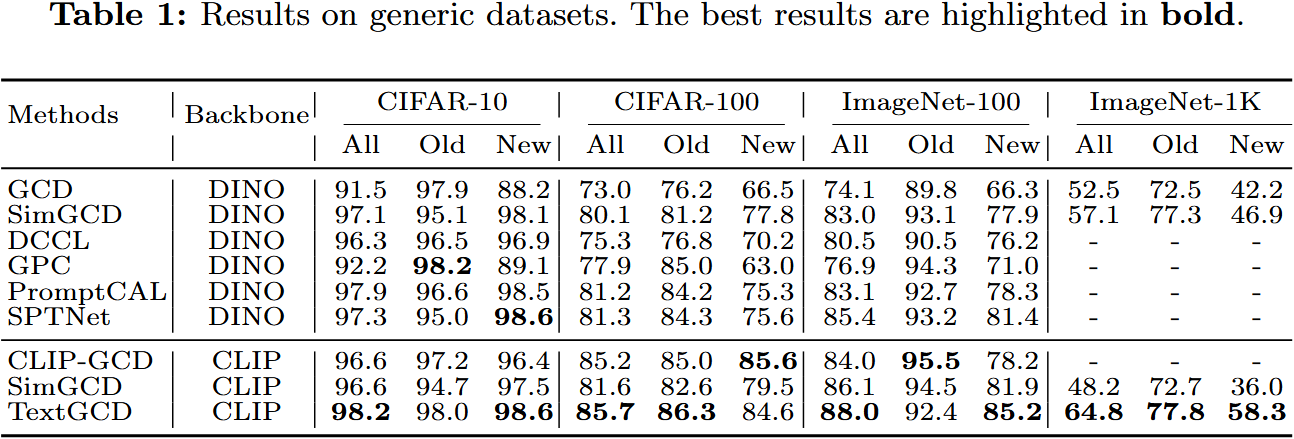
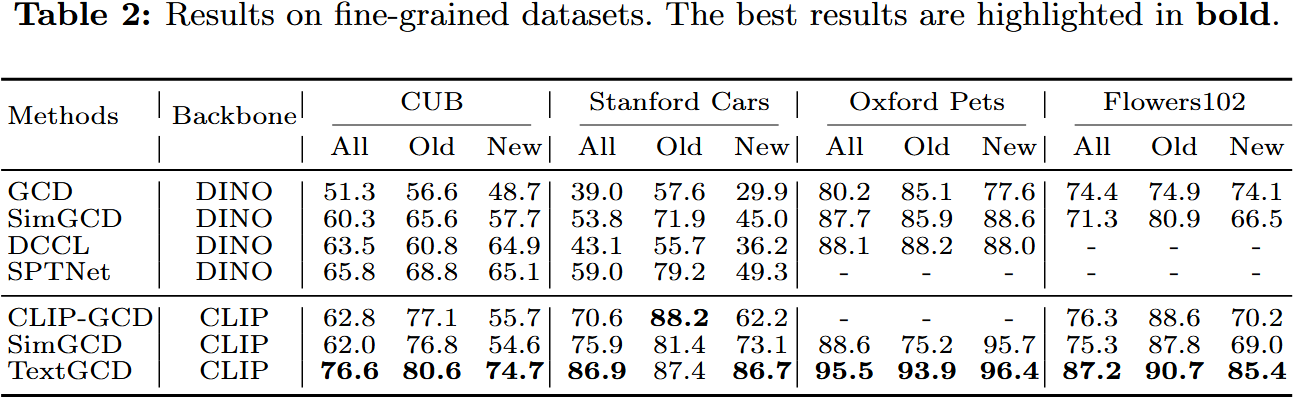
- 在八个数据集上的全面实验证明了所提方法的有效性。特别是,与领先竞争对手相比,我们的方法是 ImageNet-1 k 上的所有准确率提高了 7.7%,在 CUB 上提高了 10.8%。源代码将公开可用。
Method
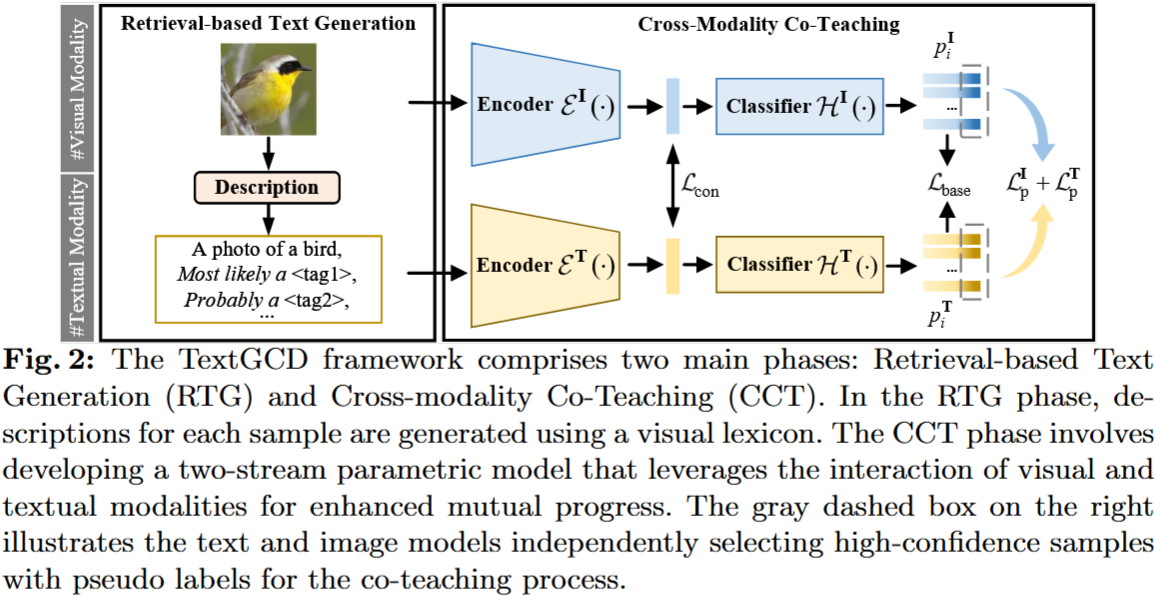
Baseline
We follow the SimGCD to build our parametric learning baseline, which consists of a supervised loss for labeled data and an unsupervised loss for both labeled and unlabeled data.
Retrieval-based Text Generation
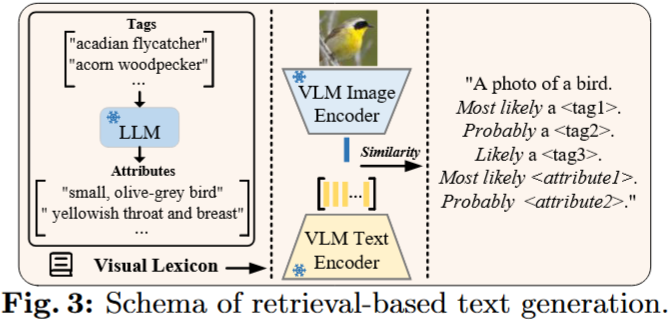
Building the Visual Lexicon. 从语义分割、目标检测和分类中建立的基准集合中聚合了多样化和广泛的标签集合。此外,利用大语言模型(如 GPT 3)通过 What are useful features for distinguishing a {tag} in a photo? 的 prompt 来进一步描述每个标签,这可用 {tag} which has the {feature} 的属性来扩充视觉词典
Tag Retrieval. 给定视觉词典,包括标签和相应的属性,我们使用一个辅助的 VLM (例如, CLIP ) 对其进行编码,从而创建文本特征库。对于每幅图像,我们使用辅助模型生成其视觉特征,然后使用余弦相似度将其与文本特征库中的条目进行比较。随后,我们识别出与图像相似度最高的最相关的 $n_t$ 个标签和 $n_a$ 个属性。然后,我们根据相似性排序将这些标签和属性的文本描述符串接起来。这个过程产生了每个图像 $x_i$ 的分类描述文本 $t_i$
Cross-modality Co-teaching
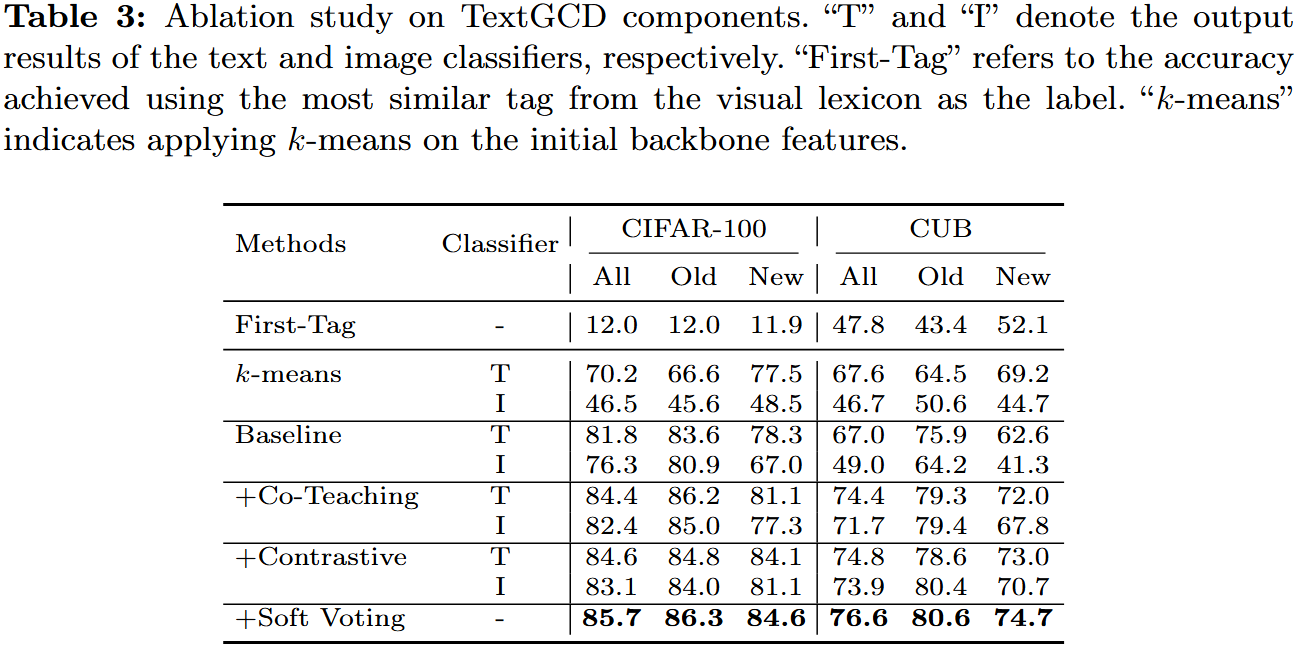
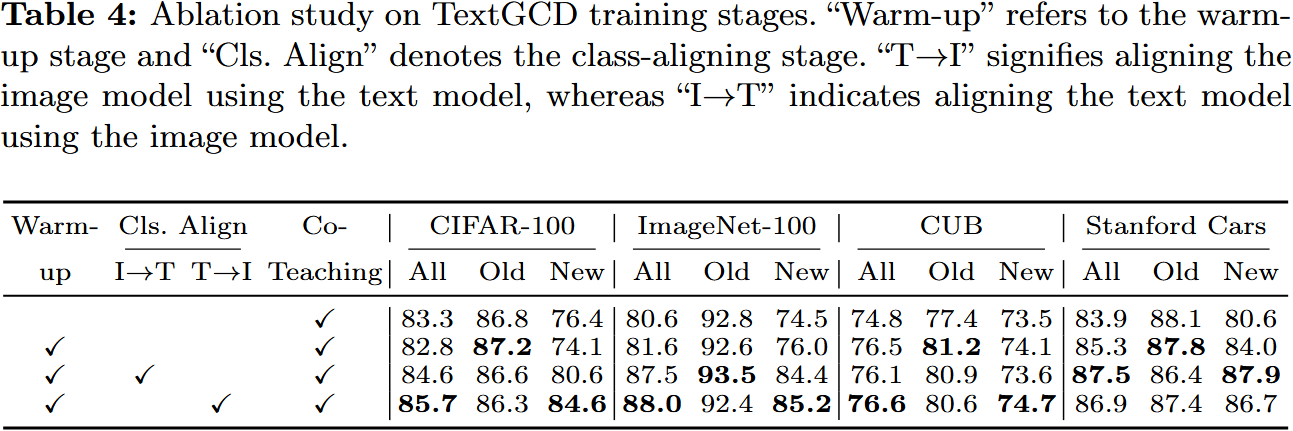
认识到模态之间的内在差异天然地满足了协同教学策略中模型差异的要求,我们提出了跨模态协同教学 ( CCT ) 阶段,以实现视觉和文本分类器的互利共赢。然而,在协同教学过程中,由于缺乏注释,出现了一个显著的挑战:每个模态的分类器经常不对齐。这种错位意味着两种模态之间的一致的课堂指标无法得到保证,这对有效的合作教学构成了很大的障碍。为了克服这个问题,我们引入了两个预备阶段:热身阶段和类对齐阶段,旨在建立模式特异性分类器的同时确保它们的对齐
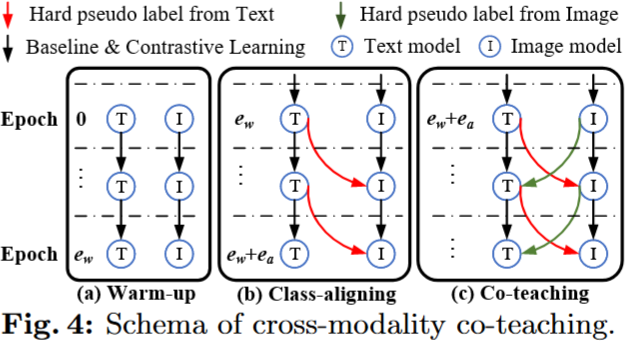
- Stage I: Warm-up. 使两个模型都能从各自的模态数据中充分学习类别知识,从而发展模式特异性类别知觉
- Stage II: Class-aligning. 该阶段旨在对齐两个模态的分类器。为此,我们在文本模型的基础上选取高置信度的样本,并将其用于指导图像模型的训练
- Stage III: Co-teaching. 在热身和排课阶段之后,我们建立了跨模态协同教学,以促进图像和文本模型之间的互利
Experiments
Conclusion
在本文中,我们介绍了一种名为 TextGCD 的新颖方法,用于广义类别发现。与仅依赖视觉模式的先前方法相比,我们额外将文本信息整合到框架中。具体来说,我们首先基于现成的类别标签构建视觉词汇表,并通过大型语言模型(LLMs)用属性对其进行丰富。随后,我们提出了一种基于检索的文本生成(RTG)方法,为每个样本分配可能的标签和相应的属性。在此基础上,我们设计了一种跨模态协同教学(CCT)策略,充分利用视觉和文本信息之间的相互优势,实现稳健且互补的模型训练。在八个基准测试上的实验表明,我们的 TextGCD 创造了新的最先进性能。我们希望这项研究能够为广义类别发现社区带来新视角,帮助框架结合基础模型和文本信息