Paper Reading
Paper Reading
持续更新中…
上次更新:2024-05-31
CompoDiff: Versatile Composed Image Retrieval With Latent Diffusion
- 摘要
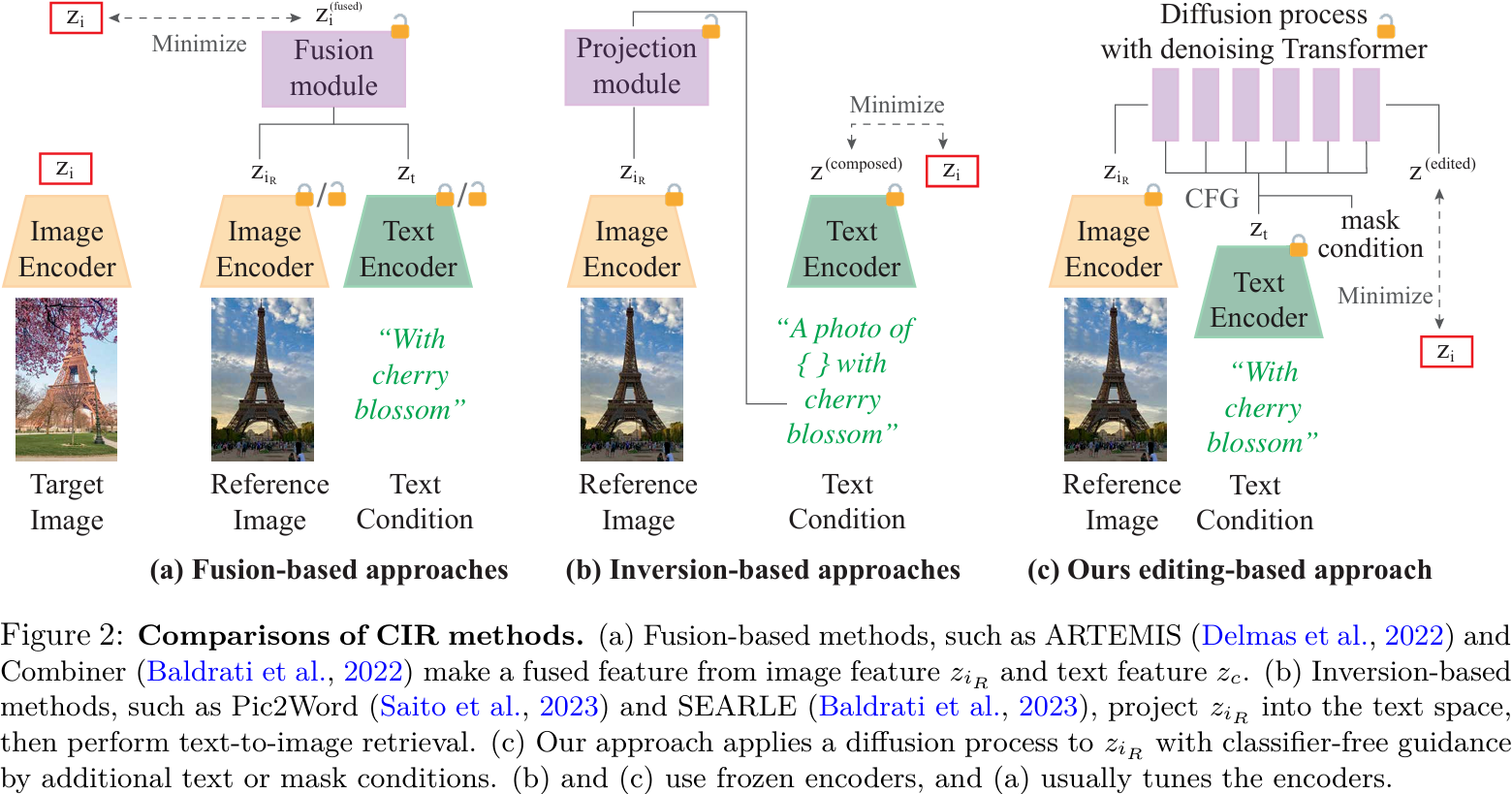
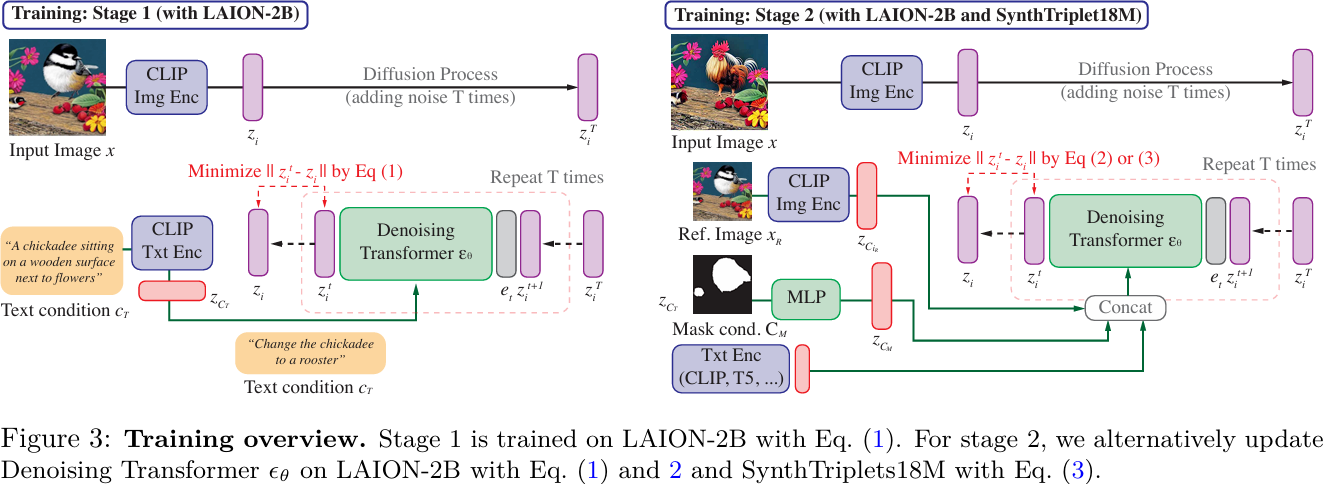
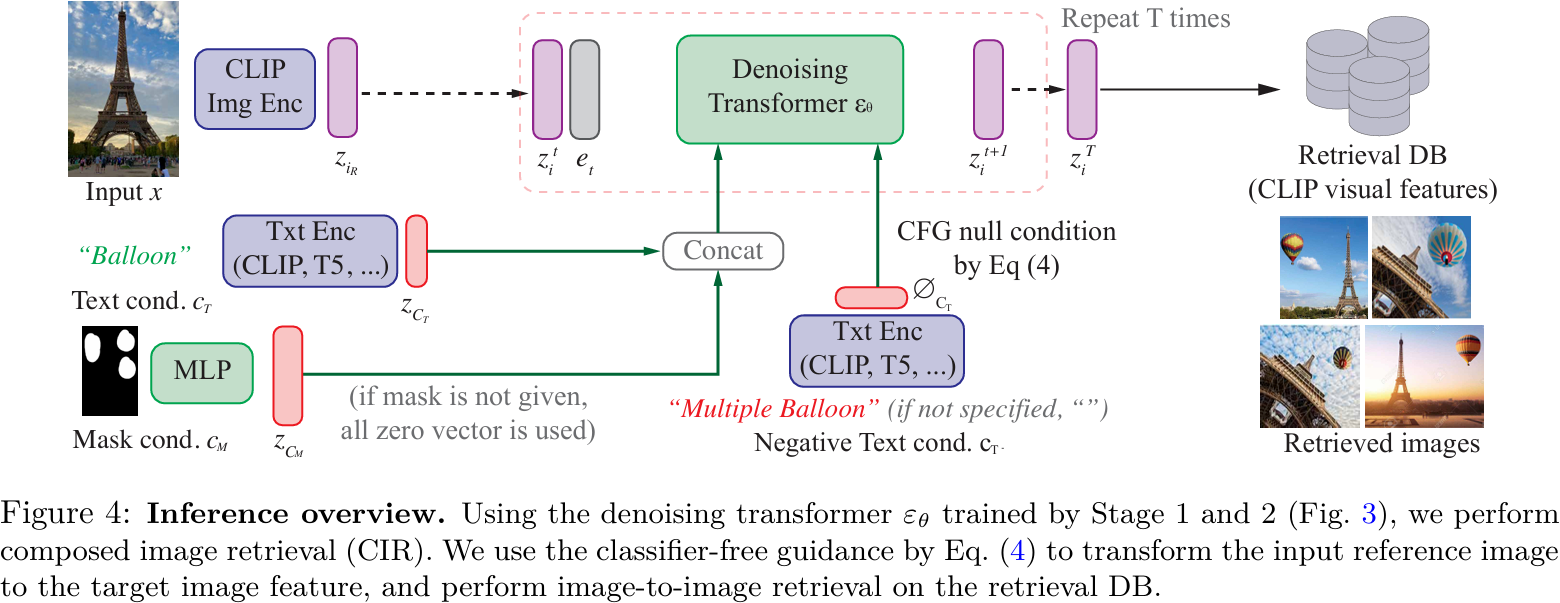
本文提出了一种新颖的基于扩散的模型CompoDiff,用于通过潜在扩散解决零样本组合图像检索(ZS-CIR)问题。本文还介绍了一个新的合成数据集,名为SynthTriplets18M,其中包含1880万张参考图像、条件和对应的目标图像三元组,用于训练CIR模型。CompoDiff和SynthTriplets18M解决了以前CIR方法的不足,例如由于数据集规模小和条件类型有限导致的泛化能力差。CompoDiff不仅在四个ZS-CIR基准测试(包括FashionIQ、CIRR、CIRCO和GeneCIS)上实现了新的最先进水平,还通过接受多种条件(如负面文本和图像掩码条件)实现了更通用和可控的CIR。CompoDiff还展示了在文本和图像查询之间条件强度的可控性以及推理速度与性能之间的权衡,这在现有CIR方法中是无法实现的。

A Survey on Deep Learning with Noisy Labels: How to train your model when you cannot trust on the annotations?
- 摘要:从互联网上自动收集的数据集、由非专业标注者甚至在医学领域等具有挑战性的任务中由专家错误标注的数据集中,常常存在噪声标签。尽管深度学习模型在不同领域显示出了显著的进步,但一个未解决的问题是它们在训练过程中记住噪声标签,从而降低了其泛化能力。由于深度学习模型依赖于正确标注的数据集,而标签的正确性难以保证,因此在深度学习训练中考虑噪声标签的存在是至关重要的。文献中提出了多种方法来改善在噪声标签存在下深度学习模型的训练。本文对文献中的主要技术进行了综述,我们将这些算法分类为以下几组:鲁棒损失、样本加权、样本选择、元学习和组合方法。我们还介绍了常用的实验设置、数据集和最新模型的结果。
噪声标签的来源主要有下面四种:
- insufficient information to provide reliable labeling, such as poor quality images
- mistake made by experts
- variability in the labeling by several experts
- data encoding or communication problems (e.g., accidental click)
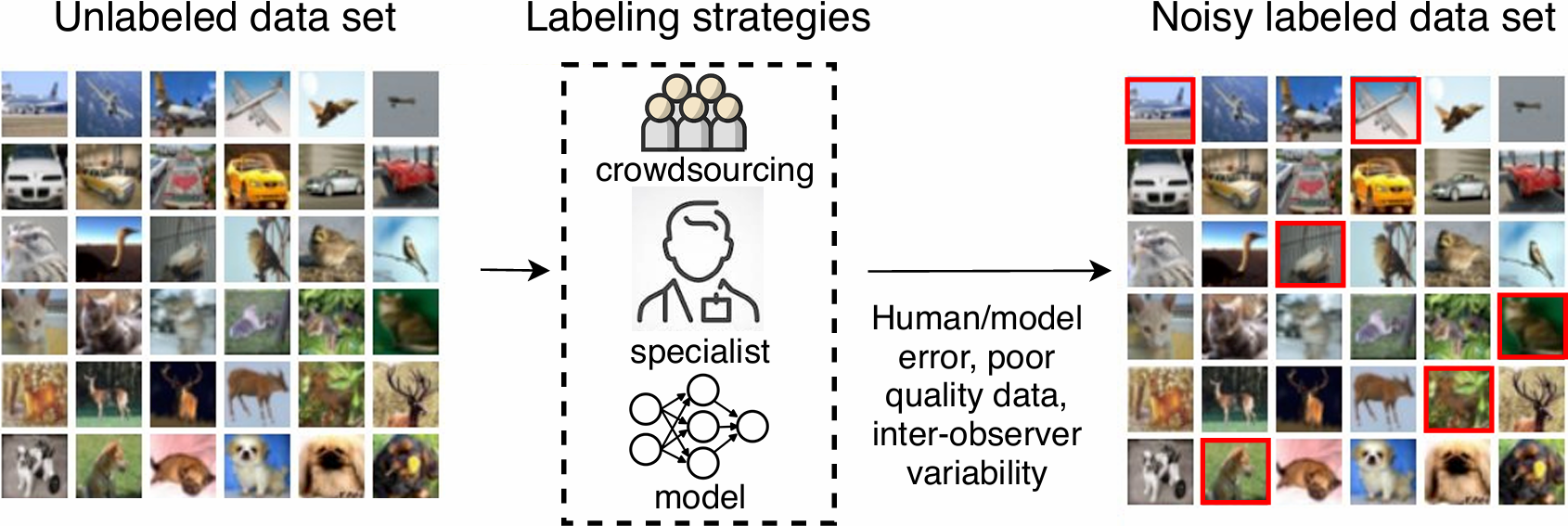 Fig. 1. Labeling process and noise sources
Fig. 1. Labeling process and noise sources
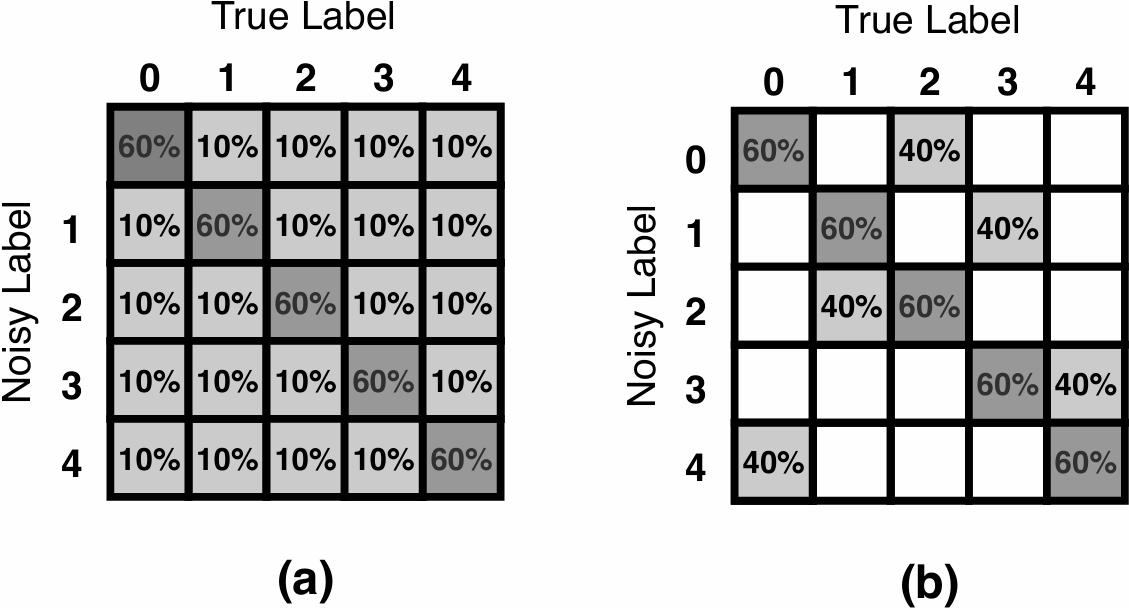 Fig. 2. Transition matrix of different noisy types: (a) symmetric, and (b) asymmetric
Fig. 2. Transition matrix of different noisy types: (a) symmetric, and (b) asymmetric
噪声标签的类型:
- Symmetric Noise:标签错误的概率对所有类别都是相同的。
- Asymmetric Noise:标签错误的概率对不同类别是不同的。
- Open-set Noise:数据集中存在未知类别。
文章对噪声学习的种类汇总为如下几类:
A. Noise Transition Matrix
B. Roubst Losses
C. Sample Weighting
D. Sample Selection
E. Meta-Learning
F. Combination Approaches
本文由作者按照 CC BY 4.0 进行授权