Paper | Multimodal Learning with Transformers: A Survey
- Title: Multimodal Learning with Transformers: A Survey (基于Transformer的多模态学习:综述)
- Authors: Peng Xu, Xiatian Zhu, and David A. Clifton
- Affiliation: Peng Xu is with Tsinghua University (清华大学). Xiatian Zhu is with the University of Surrey. David A. Clifton is with the University of Oxford, UK, and also with Oxford Suzhou Centre for Advanced Research, Suzhou, PRC.
- Keywords: Multimodal Learning, Transformer, Introductory, Taxonomy, Deep Learning, Machine Learning
- URLs: Paper
TL;DR
本篇文章对面向多模态数据的 Transformer 计算进行了全面的综述。主要包括如下内容:
- 多模态学习、Transformer 生态系统和多模态大数据时代的背景
- 从几何拓扑角度系统回顾 Vanilla Transformer、Vision Transformer 和多模态 Transformer
- 通过两个重要的范例回顾多模态 Transformer,即多模态预训练和特定多模态任务
- 总结多模态 Transformer 模型和应用程序所面临的共同挑战和设计
- 为社区提供开放问题和潜在研究方向的讨论
1. INTRODUCTION
本次调查重点关注 Transformers 的多模态学习,其灵感来自于它们在建模不同模态(例如语言、视觉、听觉)和任务(例如语言翻译、图像识别、语音识别)时的内在优势和可拓展性,具有较少的特定于模态的架构假设(例如,视觉中的平移不变性和局部网格注意偏差)。Transformer 的输入可以包含一个或多个标记序列以及每个序列的属性(比如模态标签、顺序),自然允许 MML 无需进行架构修改。最近出现了大量跨不同学科探索 Transformer 架构的研究尝试和活动,导致近年来开发了大量新颖的 MML 方法,以及各个领域的重大和多样化的进展。这就需要及时回顾和总结代表性方法,使研究人员能够了解相关学科 MML 领域的整体概况,全面了解当前成就和主要挑战
2. BACKGROUND
2.1 Multimodal Learning(MML)
MML 是近几十年来的一个重要研究领域;早期的多模式应用——视听语音识别是在 20 世纪 80 年代研究的。 MML 是人类社会的关键。我们人类生活的世界是一个多模态环境,因此我们的观察和行为都是多模态的。例如,人工智能导航机器人需要多模态传感器来感知现实世界环境,例如摄像头、激光雷达、雷达、超声波、GNSS、高清地图、里程表。此外,人类行为、情感、事件、动作和幽默是多模态的,因此各种以人为中心的 MML 任务被广泛研究,包括多模态情感识别、多模态事件表示、理解多模态幽默、面部表情-基于身体声音的视频人物聚类等
2.2 Transformers: a Brief History and Milestones
- Vision Transformer (ViT) 是一项开创性的工作,它通过将 Transformer 的编码器应用于图像来提供端到端的解决方案
- 受 Transformer 巨大成功的推动,VideoBERT 是一项突破性工作,是将 Transformer 扩展到多模态任务的第一个工作
- 2021年,CLIP 被提出。这是一个新的里程碑,它使用多模态预训练将分类转换为检索任务,使预训练模型能够解决零样本识别问题
2.3 Multimodal Big Data
最近发布的多模态数据集中出现的新趋势有:
- 数据规模更大
- 更多的模态
- 更多的场景
- 更难的任务
- 教学视频越来越受欢迎
3. TRANSFORMERS
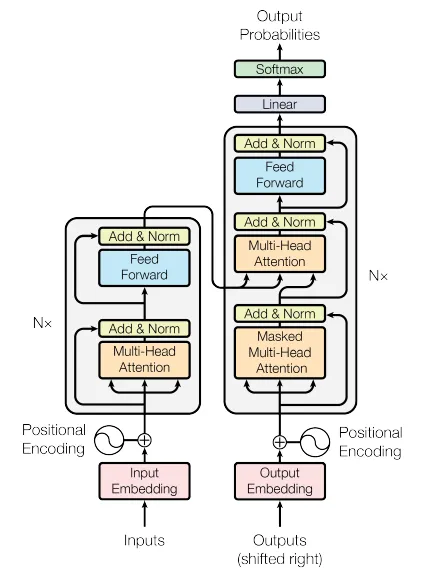
Vanilla Transformer 可以从几何拓扑的角度来理解,因为由于自注意力机制,给定来自任何模式的每个标记化输入,Vanilla self-attention (Transformer) 可以将其建模为在拓扑集合空间中的全连接图。与其他深度网络(例如,CNN 受限于对齐的网格空间/矩阵)相比,Transformers 本质上具有更通用和灵活的建模空间
3.1 Vanilla Transformer
假设输入张量为 $\mathbf{Z}$,MHSA 和 FFN 子层的输出可以表示为:
\[\mathbf{Z}\leftarrow N(sublayer(\mathbf{Z})+\mathbf{Z})\]原始的 Vanilla Transformer 对每个 MHSA 和 FFN 子层使用后归一化。然而,如果我们从数学角度考虑这一点,预归一化更有意义1。这类似于矩阵理论的基本原理,在投影之前应该进行归一化,例如Gram-Schmidt过程2。
3.1.1 Input Tokenization
- Tokenization:将词汇序列作为输入很简单,原始的自注意力可以将任意输入建模为全连接的图,与模态无关,每个 token 都可被视为图的一个节点
- Special/Customized Tokens:在 Transformer 中,各种特殊/自定义标记可以在语义上定义为标记序列中的占位符,例如掩码标记
[MASK] - Position Embedding:vanilla transformer 使用正弦和余弦函数来生成位置嵌入
Tokenization 的主要优点包括:
- 从几何拓扑角度来看,标记化是一种更通用的方法,通过最小化不同模态引起的约束来实现。Tokenization 帮助 Transformer 通过不规则的稀疏结构统一处理不同的模态
- Tokenization 是一种更灵活的方法,通过串联/堆栈、加权求和等方式组织输入信息
- Tokenization 与特定于任务的定制 token 兼容,比如用于掩码语言建模的
[MASK]、用于分类的[CLASS]
Position Embedding 的理解
位置嵌入不是必须的,而是可选的(比如点云数据),可视为一种通用的附加信息。换句话说,从数学的角度来看,可以添加任何附加信息,例如位置嵌入方式的细节,例如素描笔划的笔状态、监视中的摄像机和视点。有一项综合调查3讨论了 Transformer 中的位置信息。对于句子结构(顺序)和一般图形结构(稀疏、任意和不规则),位置嵌入可以帮助 Transformer 学习或编码底层结构。从自注意力的数学角度考虑,即缩放点积注意力,如果位置嵌入信息丢失,注意力对于单词(在文本中)或节点(在图中)的位置是不变的。因此,在大多数情况下,位置嵌入对于 Transformer 来说是必要的。
3.1.2 Self-Attention and Multi-Head Self-Attention
- Self-Attention (SA):给定一个输入序列,自注意力允许每个元素关注所有其他元素,以便自注意力将输入编码为全连接图。Transformer 家族具有全局感知的非局部能力
- Masked Self-Attention (MSA):在实际应用中,需要修改 self-attention 来帮助 Transformer 的解码器学习上下文依赖,防止位置关注后续位置
- Multi-Head Self-Attention (MHSA):在实践中,多个自注意力子层可以并行堆叠,它们的级联输出通过投影矩阵 $\mathbf{W}$ 融合,形成称为多头自注意力的结构。MHSA 帮助模型共同关注来自多个表示子空间的信息
3.1.3 Feed-Forward Network
多头注意力子层的输出将通过位置前馈网络(FFN),该网络由具有非线性激活的连续线性层组成。例如,两层 FFN 可以表示为
\[FFN(\mathbf{Z})=\sigma(\mathbf{Z}\mathbf{W}_1+\mathbf{b}_1)\mathbf{W}_2+\mathbf{b}_2\]在一些 Transformer 文献中,FFN 也称为多层感知器 (MLP)
3.2 Vision Transformer
Vision Transformer (ViT) 具有特定于图像的输入 pipeline,输入图像必须分割成固定大小(例如 $16\times16$、$32\times32$)的块。经过线性嵌入层并添加位置嵌入后,所有 patch-wise 序列将由标准 Transformer 编码器进行编码。给定图像 $\mathbf{X}\in\mathbb{R}^{H\times W\times C}$($H$ 高度、$W$ 宽度、$C$ 通道),ViT 需要将 $\mathbb{X}$ 重塑为一系列展平的 2D patch:$\mathbf{x}_p\in\mathbb{R}^{N\times P^2\times C}$,其中 $(P\times P)$ 是 patch 大小,$N = HW/P^2$。要执行分类,标准方法是在嵌入 patch 序列中添加额外的可学习嵌入“分类标记” [CLASS] :
其中 $\mathbf{W}$ 表示投影
3.3 Multimodal Transformers
最近,大量 Transformer 已针对各种多模态任务进行了广泛研究,并被证明与判别性和生成性任务中的各种模态兼容
3.3.1 Multimodal Input
Transformer 系列是一种通用架构,可以表示为一种通用图神经网络。具体来说,自注意力可以通过关注全局(非局部)模式将每个输入处理为完全连接的图。因此,这种内在特征有助于 Transformer 在与各种模态兼容的模态不可知管道中工作,通过将每个标记的嵌入视为图的节点
- Tokenization and Embedding Processing
下表总结了 Transformers 多模态输入的一些常见做法,包括 RGB、视频、音频/语音/音乐、文本、图形等
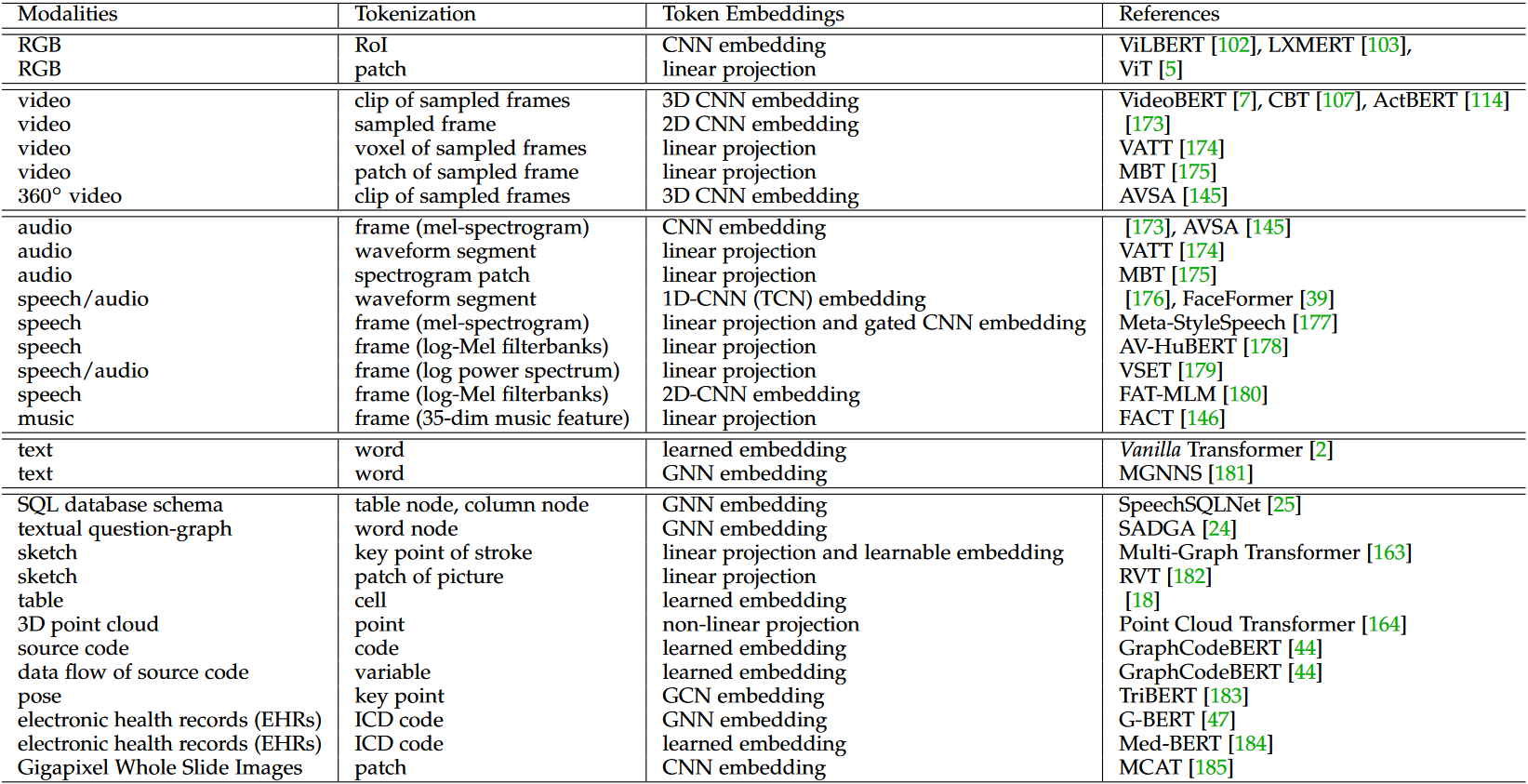
从几何拓扑的角度考虑时,表中列出的每种模态都可以被视为一个图。 RGB 图像本质上是像素空间中整齐的网格图。视频和音频都是涉及时间和语义模式的复杂空间上基于剪辑/片段的图。如果我们沿着绘图笔划考虑它们的关键点,2D 和 3D 绘图草图都是一种稀疏图。与草图类似,人体姿势也是一种图形。 3D点云是一个图,其中每个坐标都是一个节点。其他抽象模式也可以解释为图,例如源代码、源代码的数据流、表、SQL数据库模式、文本问题图和电子健康记录(电子病历)
- Token Embedding Fusion
在实践中,Transformers 允许每个 token 位置包含多个嵌入。对于单模态和多模态 Transformer 模型来说,这本质上是一种嵌入的早期融合。最常见的融合是多个嵌入的 token-wise 求和。token embedding fusion 在多模态 Transformer 应用中具有重要作用,因为各种嵌入可以通过 token-wise 运算符融合
3.3.2 Self-Attention Variants in Multimodal Context
在多模态 Transformer 中,跨模态交互(例如融合、对齐)本质上是通过自注意力及其变体来处理的。从自注意力设计的角度来看,基于 Transformer 的多模态模型的设计方式有如下几种:
- 早期求和(token-wise,加权)
- 早期串联
- 分层注意力(多流到单流)
- 分层注意力(单流到多流)
- 交叉注意力
- 交叉注意力连接
下面从一张表和一个图来快速了解:


从交互时间的角度来看,这些多模态注意力分为三类,即
- 早期交互(early interaction):早期求和、早期串联和层次注意力(单流到多流)
- 后期交互(late interaction):层次注意力(多流到多流、单流)
- 整个交互(throughout interaction):交叉注意力、交叉注意力到串联
4. APPLICATION SCENARIOS
4.1 Transformers for Multimodal Pretraining
4.1.1 Task-Agnostic Multimodal Pretraining
在现有的工作中,出现了以下主要趋势:
- 视觉语言预训练(VLP)是该领域的一个主要研究问题
- 语音可以用作文本
- 过度依赖对齐良好的多模态数据
- 大多数现有的 pretext tasks 可以很好地跨模式迁移
- 模型结构主要分为三类:单流、多流以及混合流
- 跨模式交互可以在预训练 pipeline 中的各个组件/级别内执行
两阶段 pipeline 具有一个主要优势——通过使用监督预训练的视觉检测器实现对象感知,然而这些都基于一个强烈的假设,即视觉表示可以固定
- Pretext Tasks
在基于 Transformer 的多模态预训练中,pretraining tasks 也称为 pretext tasks。这些与下游任务无关的 pretext tasks 是可选的,下游任务目标可以直接训练。下表提供了基于 Transformer 的多模态预训练的常见且有代表性的 pretext tasks:
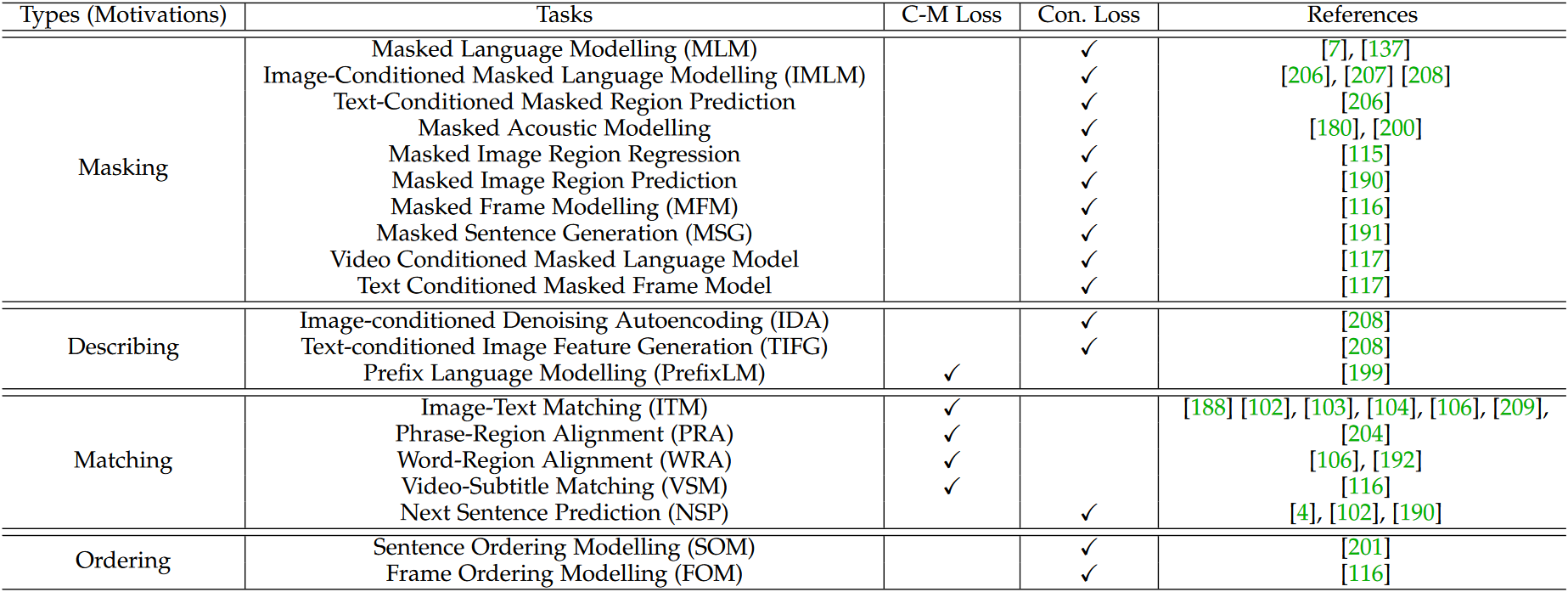
pretext tasks 有多种分类法:
- 监督。如果我们从监督中考虑 pretext tasks 的定义,pretext 可以分为无监督/自监督(例如,掩码语言建模(MLM))和监督(例如,图像-文本匹配(ITM))等。如今,自监督占大多数
- 模态。可分为单模态或多模态。不过有些单模态任务仍然用到了多模态的信息
- 动机。如果考虑到他们的动机,pretext tasks 包括 masking、describing、matching、ordering 等
本文从如下角度对比 VLP Transformer 模型:
- Transformer 生态系统的核心是 self-attention,因此我们将从 self-attention 或其变体如何以及何时进行跨模态交互的角度来比较现有的多模态预训练 Transformer 模型
- 从几何拓扑角度考虑,自注意力通过将每个 token 的嵌入作为图的节点来帮助 Transformer 本质上在与各种模态兼容的模态不可知 pipeline 中工作,因此我们要强调的是,现有的 VLP 可以应用于视觉和语言领域之外的其他模式
- 我们建议将基于 Transformer 的多模态预训练 pipeline 视为具有三个关键组成部分,从下到上,即 tokenization、Transformer representation、objective supervision
多模态预训练 Transformer 方法仍然存在一些明显的瓶颈。虽然 BERT 式的跨模态预训练模型在各种下游视觉语言任务上产生了出色的结果,但它们无法直接应用于生成任务。因此,如何设计更统一的 pipeline,既可以用于判别性任务,又可以用于生成性下游任务,也是一个有待解决的开放问题
作为预训练任务的掩码语言和区域建模有一个主要优点,即从这些监督中学习的 Transformer 编码器可以基于双向上下文对视觉和语言模式进行编码,并且自然地适合语义理解任务,例如 VQA、图像文本检索
4.1.2 Task-Specific Multimodal Pretraining
在多模态 Transformer 的实践中,上述下游任务无关的预训练是可选的,不是必需的,下游任务特定的预训练也被广泛研究。主要原因包括:
- 受现有技术的限制,设计一套通用性强的网络架构、pretext 任务和语料库以适应各种下游应用是极其困难的
- 各种下游应用之间存在不可忽视的差距,例如任务逻辑、数据形式,使得从预训练到下游应用的转移变得困难
因此,大量的下游任务仍然需要量身定制的预训练来提高性能
4.2 Transformers for Specific Multimodal Tasks
Transformer 模型可以在经典和新颖的判别应用中对各种多模态输入进行编码。与此同时,Transformer 还有助于各种多模式生成任务
5. CHALLENGES AND DESIGNS
我们从技术挑战的角度进一步审视之前的工作
5.1 Fusion
一般来说,MML Transformer 主要在三个级别融合多种模态的信息:输入(即早期融合)、中间表示(即中间融合)和预测(即后期融合)。我们注意到,在 MML Transformers中,基于简单预测的后期融合的方法较少被采用。考虑到学习更强大的多模态上下文表示的动机和计算能力的巨大进步,这是合理的。为了增强和解释MML的融合,探索模态之间的交互和融合的测量将是一个有趣的研究方向
5.2 Alignment
跨模式对齐是许多现实世界多模式应用的关键。基于 Transformer 的跨模式对齐已经针对各种任务进行了研究。一种代表性的做法是将两种模态映射到一个共同的表示空间中,并通过配对样本进行对比学习
5.3 Transferability
可迁移性是基于 Transformer 的多模态学习的主要挑战,涉及如何跨不同数据集和应用程序迁移模型的问题。数据增强和对抗性扰动策略帮助多模态 Transformer 提高泛化能力。
CLIP给社区带来的主要启发是,通过使用提示模板 A photo of a {label},可以将预训练的多模态(图像和文本)知识转移到下游零样本图像预测。弥合训练和测试数据集之间的分布差距。
过度拟合(over-fitting)是迁移的主要障碍。由于建模能力强,多模态 Transformer 在训练期间可能会过度拟合数据集偏差
跨任务差距是转移的另一个主要障碍。在实际应用中,由于模态缺失的问题,多模态预训练 Transformer 有时需要在推理阶段处理单模态数据
基于 Transformer 的多模态学习的可迁移性还应考虑跨语言差距,例如从英语到非英语多模态环境的通用跨语言泛化
5.4 Efficiency
多模态 Transformer 面临两个主要的效率问题:
- 由于模型参数容量大,它们需要大量数据,因此依赖于大规模的训练数据集
- 它们受到时间和内存复杂性的限制,这些复杂性随输入序列长度呈二次方增长,这是由自注意力引起的
为了提高多模式 Transformer 的训练和/或推断效率,最近的努力尝试寻找各种解决方案,以使用更少的训练数据和/或参数。主要思想可概括如下:
- 知识蒸馏。将经过训练的大型 Transformer 中的知识提炼到较小的 Transformer 上
- 模型的简化和压缩。删除组件以简化 pipeline
- 不对称的网络结构。为不同的模态适当分配不同的模型容量和计算量,以节省参数
- 提高训练样本利用率
- 对模型压缩和剪枝。搜索多模态 Transformer 的最佳子结构/子网络
- 优化 self-attention 的复杂度
- 优化基于自注意力的多模态交互/融合的复杂性
- 其它优化策略。使用最优策略执行基于 Transformer 的常见多模态交互
5.5 Robustness
在大规模语料库上预训练的多模态 Transformer 实现了各种多模态应用的最先进水平,但其鲁棒性仍不清楚且尚未得到充分研究。这至少涉及到两个关键的挑战,即如何从理论上分析鲁棒性,如何提高鲁棒性
虽然前人有过一些研究,主要瓶颈在于学术界缺乏分析 Transformer 家族的理论工具。最近的尝试主要使用两种简单的方法来提高多模态 Transformer 模型的鲁棒性:
- 基于增强和对抗性学习的策略
- 细粒度损失函数
5.6 Universalness
由于多模态学习的任务和模式的高度多样性,通用性是多模态 Transformer 模型的一个重要问题。最近的大量尝试研究如何使用尽可能统一的管道来处理各种模态和多模态任务。理想情况下,统一的多模态 Transformer 可以与各种数据(例如对齐和未对齐、单模态和多模态)和任务(例如监督和无监督、单模态和多模态、判别式和生成式)兼容,同时具有 few-shot 甚至zero-shot 泛化能力。因此,当前多模态 Transformer 通用性目标的解决方案只是初步探索
目前 unifying-oriented 的尝试主要包括:
- 统一单模态和多模态输入/任务的管道
- 统一多模态理解和生成的管道
- 任务本身的统一和转换。例如,CLIP 将零样本识别转换为检索,从而降低了修改模型的成本
然而,上述做法遇到了一些明显的挑战和瓶颈,至少包括:
- 由于模态和任务的差距,通用模型应考虑通用性和成本之间的权衡
- 多任务损失函数增加了训练的复杂度
5.7 Interpretability
Transformer 在多模态学习中表现如此出色的原因和方式已被研究。这些尝试主要使用探测任务和消融研究。迄今为止,多模式 Transformer 的可解释性仍然没有得到充分研究
6. DISCUSSION AND OUTLOOK
设计通用的多模态学习(MML)模型,以在所有单模态和多模态下游任务中同时表现出色,是一个非常具有挑战性的任务。当前存在的多模态 Transformer 模型在特定的 MML 任务上表现出色,但对于设计任务不可知的 MML 架构仍然是一个开放性挑战。此外,现有的模型设计仍存在与最终目标之间的明显差距。因此,需要更多的研究来解决这些问题。在进行更精细的 MML 时,发现跨模态的潜在语义对齐至关重要。在这方面的研究需要耗费大量的计算成本,而且需要丰富的资源。此外,随着学习规模的不断扩大,训练数据变得不可避免地嘈杂和异质化。因此,正确处理噪声问题是非常有用的。此外,针对 MML 的训练策略以及如何更有效地利用 Transformer 的复杂性等问题也需要更多的研究
识别 Transformer 在多模态机器学习中的优势是一个重大的开放性问题。从文献中可以总结出以下几个主要观点:
- Transformers 能够编码隐含知识
- 多头注意力机制增强了模型的表达能力,类似于集成学习
- Transformers 具有全局聚合的特性,能够感知非局部模式
- 大型 Transformer 模型通过在大规模语料库上进行预训练,更好地处理领域差距和转移
- Transformers 可以表示输入为图形,适用于多模态数据
- 对于序列模式,如时间序列,相比基于 RNN 的模型,Transformers 具有更高的训练和推断效率
- 标记化使得 Transformers 能够灵活组织多模态输入
7. CONCLUSION
本调查重点关注使用 Transformers 的多模态机器学习。文章通过介绍在多模态环境下的 Transformer 设计和训练来回顾这个领域的现状。文章总结了这个新兴且令人兴奋的领域的关键挑战和解决方案。此外,还讨论了开放性问题和潜在的研究方向。文章作者希望这个调查为新研究人员和实践者提供一个有用且详细的概述,为相关专家(例如多模态机器学习研究人员、Transformer 网络设计师)提供一个方便的参考,并鼓励未来的进展