Paper | End-to-End Object Detection with Transformers
TL;DR
本文介绍了一种基于 Transformer 的端到端目标检测方法DETR。与传统的方法不同,DETR 直接预测对象的边界框和类别标签,避免了繁琐的后处理步骤。文章详细介绍了 DETR 的损失函数和模型结构,并通过实验证明了 DETR 在 COCO 数据集上与 Fastee R-CNN 相当甚至更好的性能。此外,DETR 的设计还可以扩展到其他复杂任务,如全景分割
1. Introduction
object detection 的目的是在图像中预测每个感兴趣对象的边界框和类别标签。现有的绝大部分方法通过使用大量的 proposals、anchors 或 window centers 来对问题进行定义,并间接地解决预测任务。这些方法严重依赖后处理步骤,比如非极大值抑制之类的方法。本文的方法是一个端到端的方法,通过直接预测来绕过很多繁琐的步骤
文章通过将 object dection 视为直接集合预测问题来简化训练流程,并采用基于 Transformer 的编/解码器架构进行预测。由于 Transformer 的自注意力机制明确地模拟了序列中元素之间的所有成对交互,使得这些架构特别适合集合预测的特定约束,比如删除重复的预测

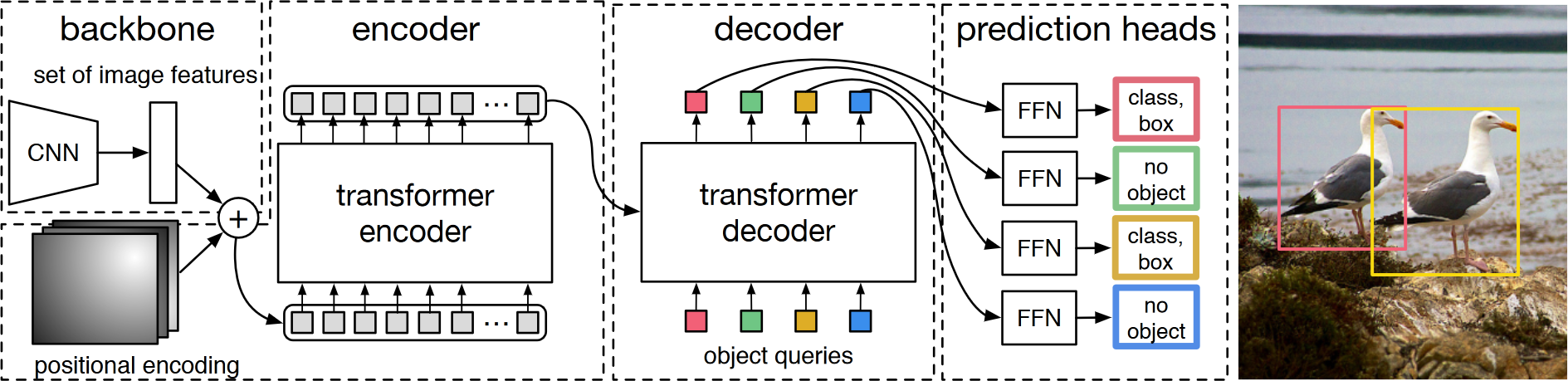
上图是 DETR 一次前向过程的简化。DETR 通过 CNN 与 Transformer 架构相结合来并行预测最终的检测集合。在训练过程中,使用二分匹配唯一地将预测与 ground truth 框分配。没有匹配的预测应该产生“无对象”($\phi$)类预测
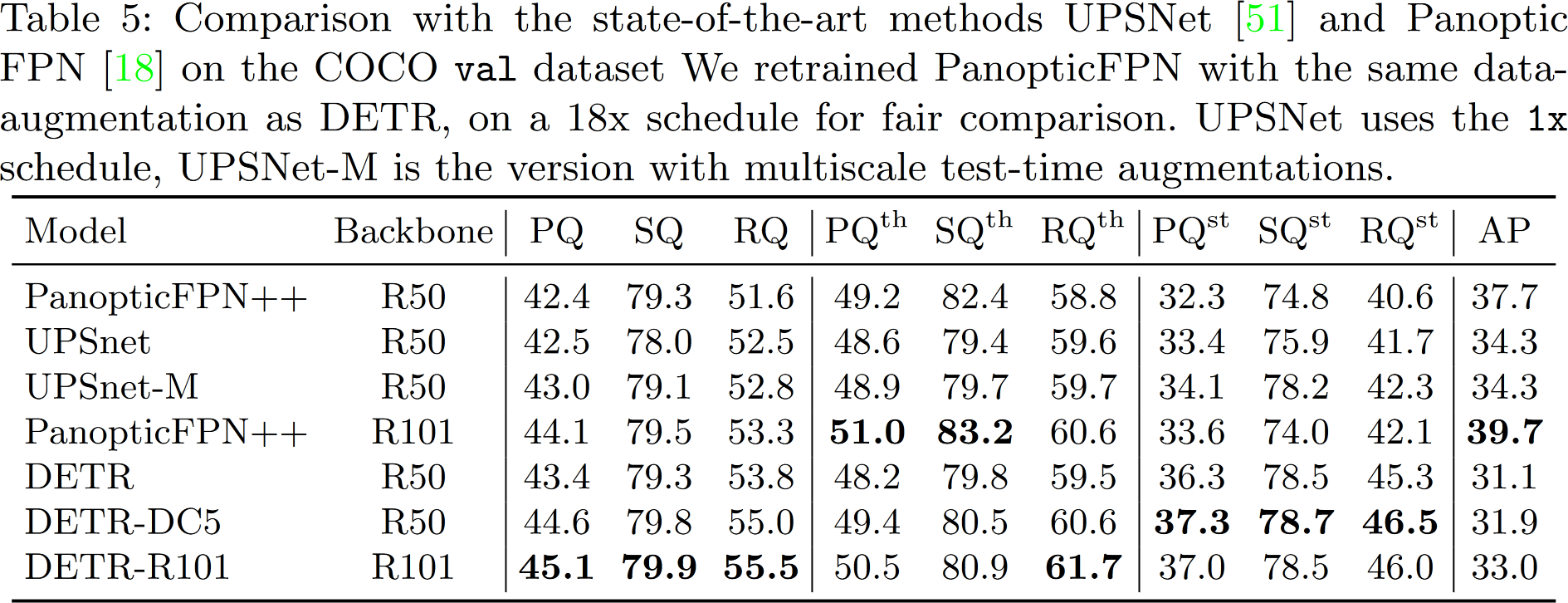
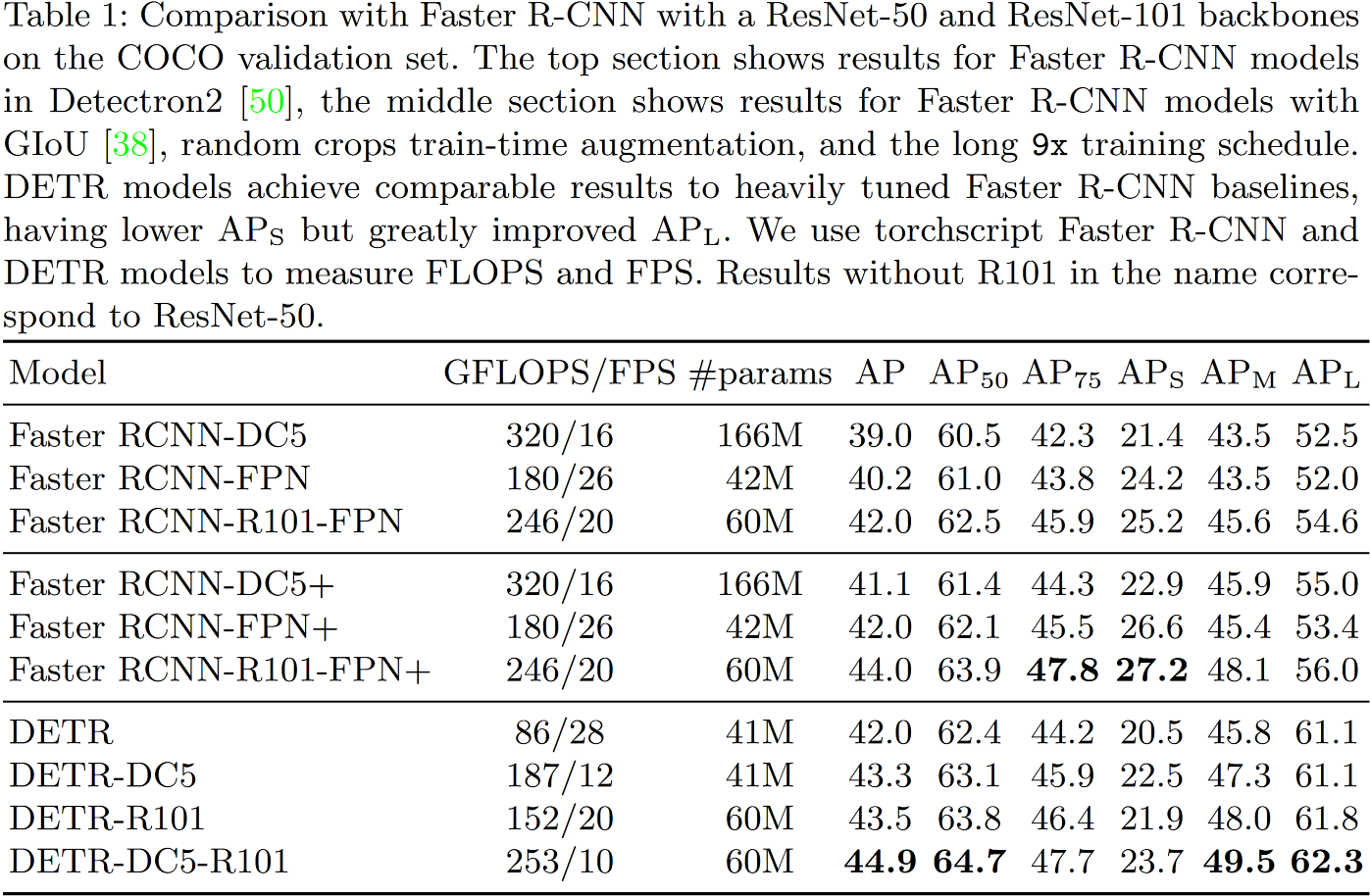
文章还在 COCO 上和 Faster R-CNN 进行对比实验,并发现 DETR 可以与之达到相当的结果,尤其是在大型物体上表现出更好的性能,这可能是由于 Transformer 的非局部性引起的。不过,DETR 在小物体上的性能较低,这也是后续可改进的方向
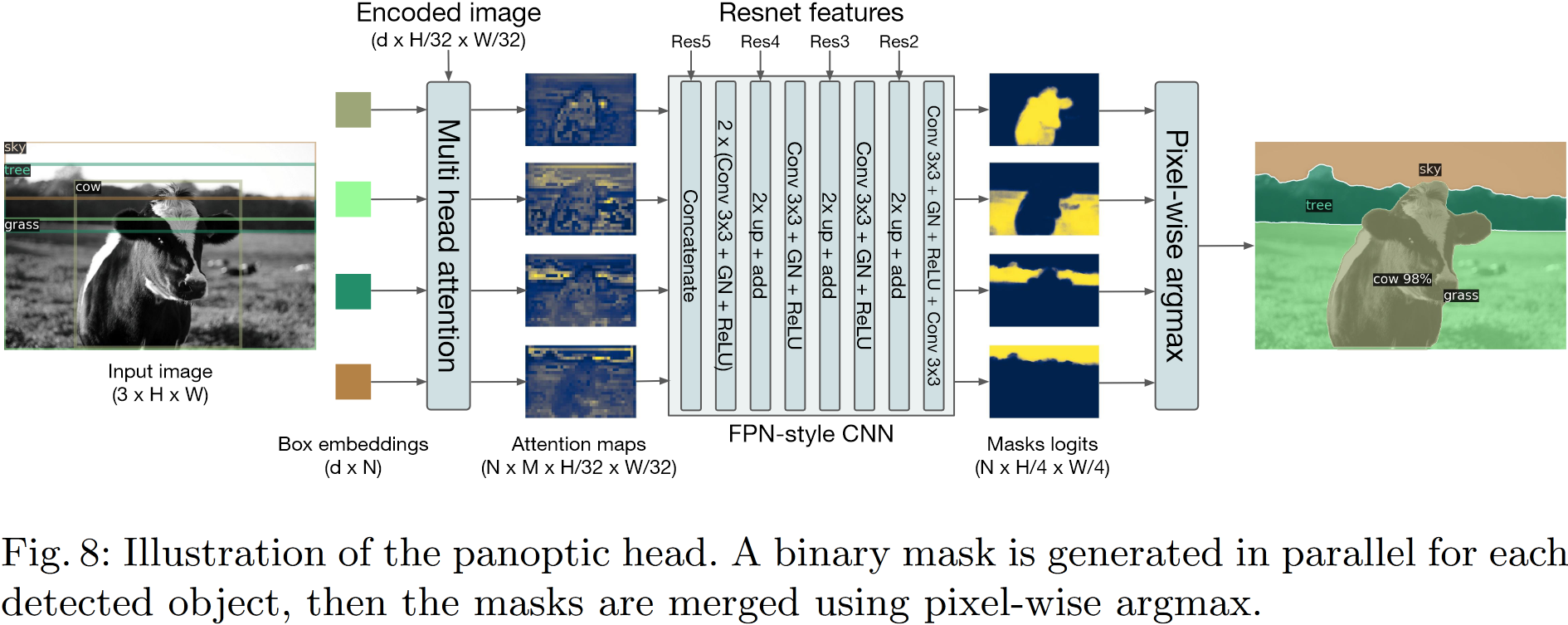
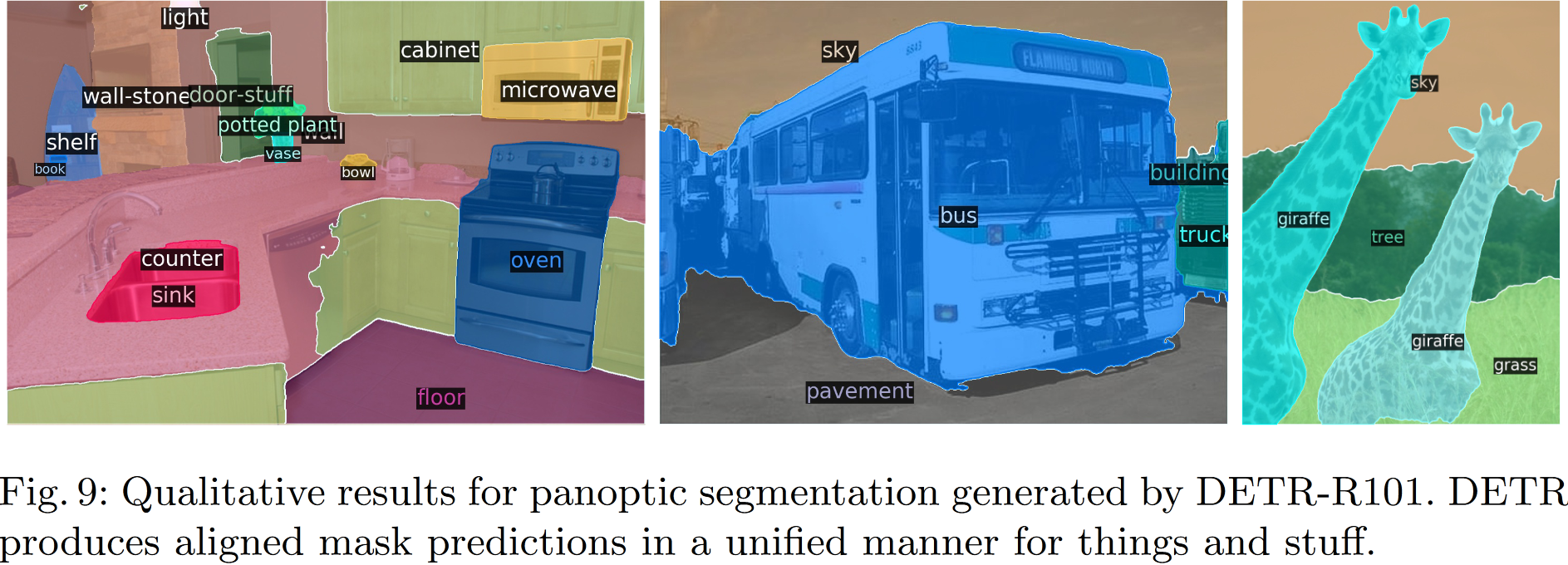
DETR 的设计可以轻松扩展到更复杂的任务。比如,在预训练的 DETR 之上训练的简单分割头优于全景分割(Panoptic Segmentation)上的 baseline 方法
2. Related work
3. The DETR model
3.1 Object detection set prediction loss
文章首先介绍的不是模型的结构,而是损失函数,可见这个损失函数对于整个算法的作用。先前的 object detection 方法会对同一个对象生成多个不同的候选框,需要使用非极大值抑制1选择最优的候选框,这样的后处理不但提高了算法的复杂度,还增加了模型调优的难度。而 DETR 是一个端到端方法,一次性就能得到正确的候选框和分类结果,这也要归功于 DETR 的损失函数设计
首先,DETR 的结果是由 $N$ 个 object queries 通过 transformer decoder 得到 $N$ 个不同的预测,这里 $N$ 被设置为明显大于图中的对象数量。用 $y$ 表示对象的 ground truth 集,$\hat{y}=\{\hat{y}_i\}^N$ 表示 $N$ 个预测的集合,$y$ 用 $\phi$ 填充到和 $\hat{y}$ 一样的大小。为了找到这两个集合之间的二分匹配,我们需要找到一个成本最低的排列方式:
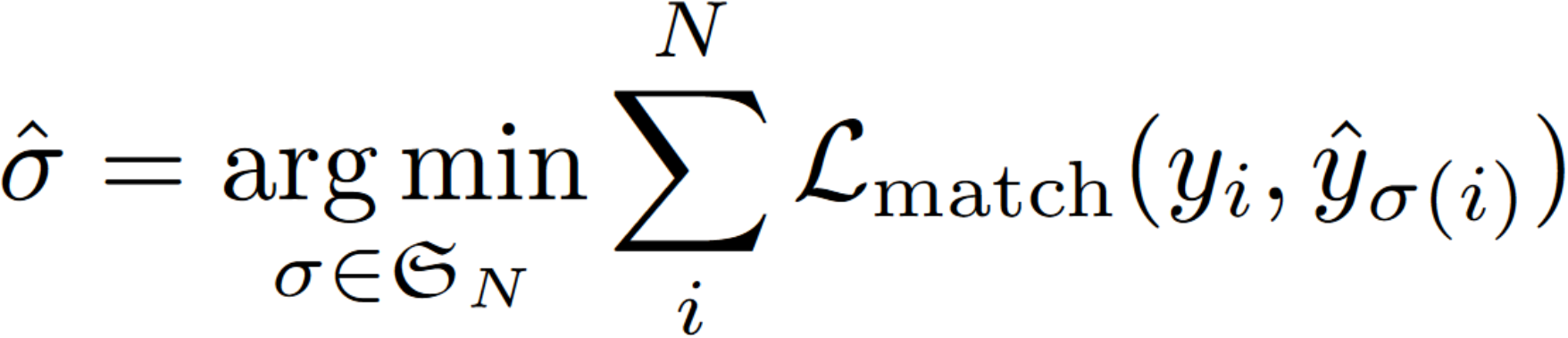
这里 $\mathcal{L}_{match}$ 是真实值 $y_i$ 与索引为 $\sigma (i)$ 的预测之间的成对匹配成本,计算公式如下:
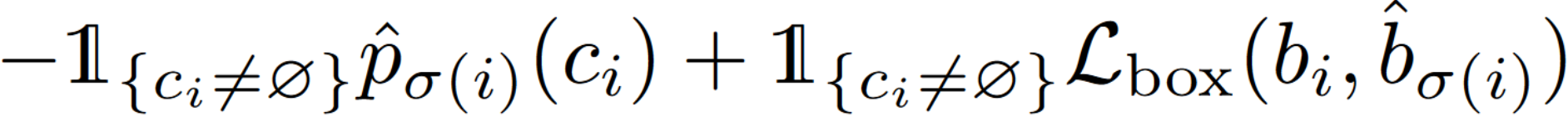
上式中 $c_i$ 表示目标类标签,$\hat{p}$ 为正确预测为类别 $c_i$ 的概率,预测框被定义为 $\hat{b}$。这个匹配过程与将 proposal 或 anchor 与 ground truth 匹配有相同的作用,主要区别是,本方式直接找到一对一的匹配,而没有重复。下一步是计算损失函数,考虑到类的不平衡性(比如空类),这里使用对数概率项进行计算:
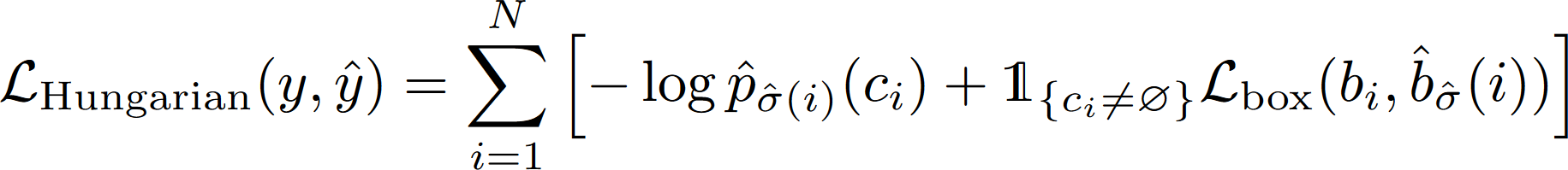
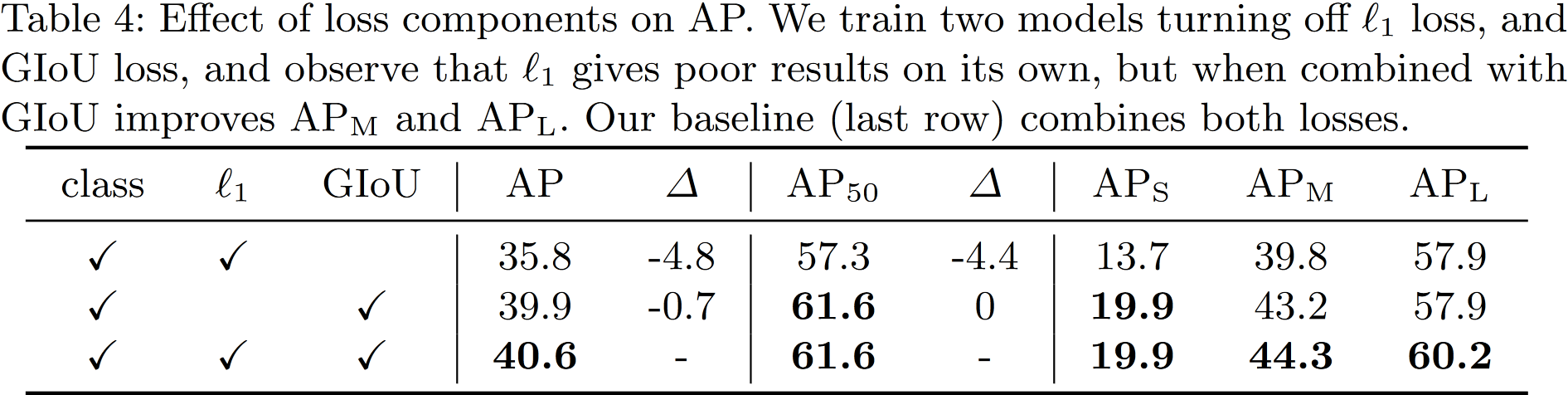
Bounding box loss:文章直接使用 box prediction。虽然这样简化了实现,但是产生缩放损失的问题,为了缓解这个现象,还要使用 IoU 损失。所以,最终的 box loss为:
\[\mathcal{L}(b_i,\hat{b}_{\sigma(i)})=\lambda_{iou}\mathcal{L}_{iou}(b_i,\hat{b}_{\sigma(i)})+\lambda_{L1}\lVert b_i-\hat{b}_{\sigma(i)}\rVert_1\]3.2 DETR architecture
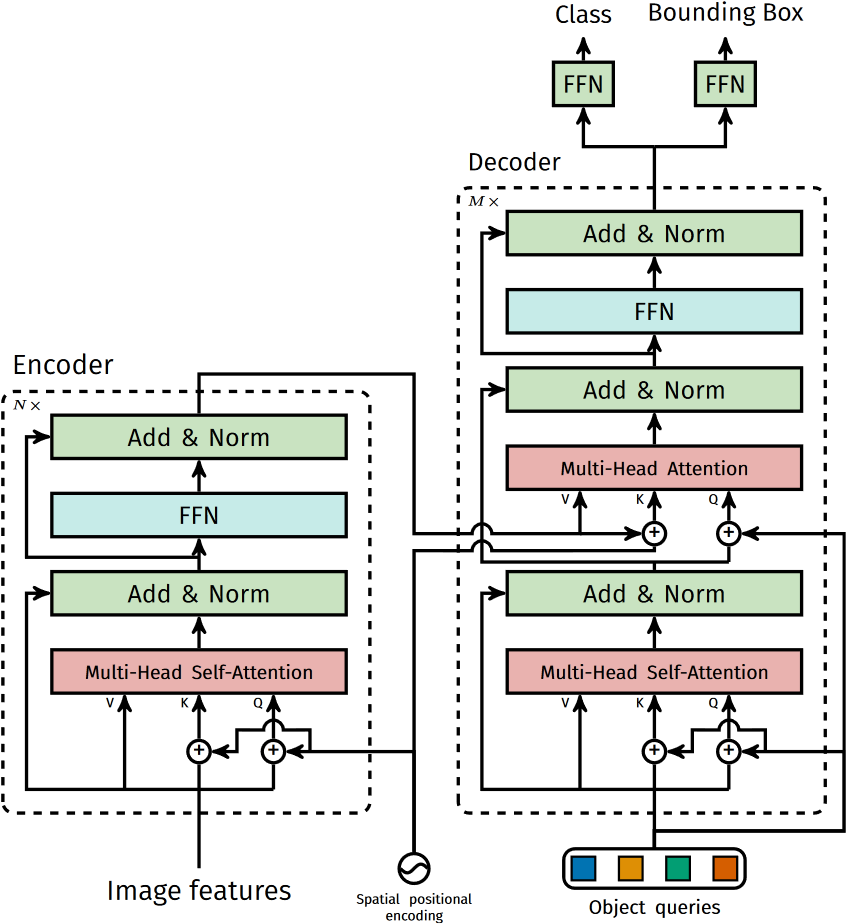
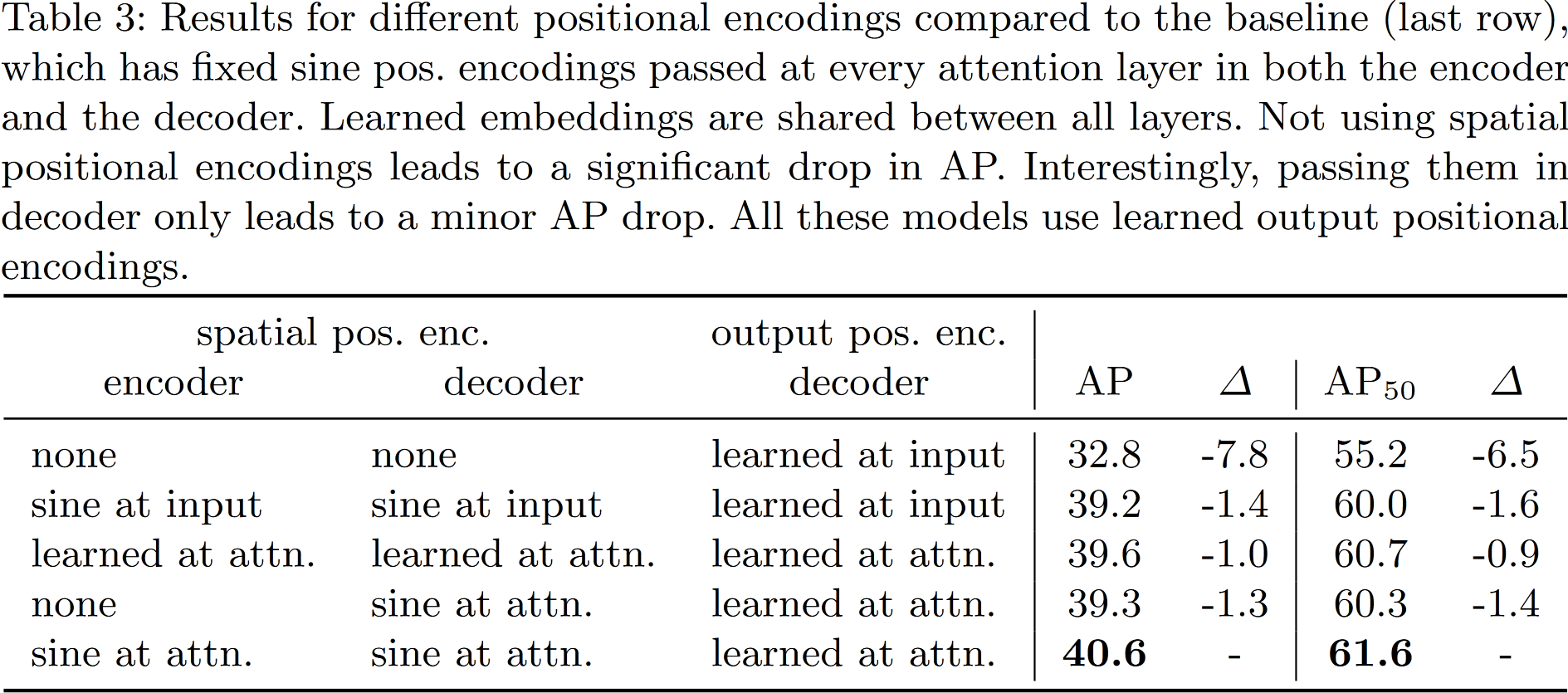
DETR 的结构简单直接,其实就是直接将 Transformer 编/解码器集成进来。先用一个 CNN 抽取特征(那个时候 ViT 还没出来),将特征展平并送入 Transformer Encoder-Decoder 与 object queries 进行交叉注意力操作,最后通过 FFN 就可得到最终预测的类别和物体框。注意在 decoder 中,所有 $N$ 个预测是同时得到的,而不是像先前的方式(使用掩码自回归)一次得到一个结果。下图是 DETR 使用的 Transformer 主要结构,其中主要需要注意的就是位置编码的添加位置
Auxiliary decoding losses:在训练过程中在解码器中使用辅助损失是有帮助的,特别是为了帮助模型输出每个类别的正确对象数量。作者在每个解码器层之后添加预测 FFN(Feed-Forward Network)和匈牙利损失。所有预测 FFN 共享参数。使用额外的共享层归一化器来将来自不同解码器层的预测 FFN 的输入进行归一化。文章在附录还贴心的给出了 DETR 的 Pytorch 一次前向的实现,虽然与最终的实现相比简化了很多,但仍可一窥 DETR 的简洁
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
import torch
from torch import nn
from torchvision.models import resnet50
class DETR(nn.Module):
def __init__(self, num_classes, hidden_dim, nheads,
num_encoder_layers, num_decoder_layers):
super().__init__()
# We take only convolutional layers from ResNet-50 model
self.backbone = nn.Sequential(*list(resnet50(pretrained=True).children())[:-2])
self.conv = nn.Conv2d(2048, hidden_dim, 1)
self.transformer = nn.Transformer(hidden_dim, nheads,
num_encoder_layers, num_decoder_layers)
self.linear_class = nn.Linear(hidden_dim, num_classes + 1)
self.linear_bbox = nn.Linear(hidden_dim, 4)
self.query_pos = nn.Parameter(torch.rand(100, hidden_dim))
self.row_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
self.col_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
def forward(self, inputs):
x = self.backbone(inputs)
h = self.conv(x)
H, W = h.shape[-2:]
pos = torch.cat([
self.col_embed[:W].unsqueeze(0).repeat(H, 1, 1),
self.row_embed[:H].unsqueeze(1).repeat(1, W, 1),
], dim=-1).flatten(0, 1).unsqueeze(1)
h = self.transformer(pos + h.flatten(2).permute(2, 0, 1),
self.query_pos.unsqueeze(1))
return self.linear_class(h), self.linear_bbox(h).sigmoid()
detr = DETR(num_classes=91, hidden_dim=256, nheads=8,
num_encoder_layers=6, num_decoder_layers=6)
detr.eval()
inputs = torch.randn(1, 3, 800, 1200)
logits, bboxes = detr(inputs)
4. Experiments
4.1 Comparison with Faster R-CNN
Training the baseline model for 300 epochs on 16 V100 GPUs takes 3 days, with 4 images per GPU (hence a total batch size of 64).
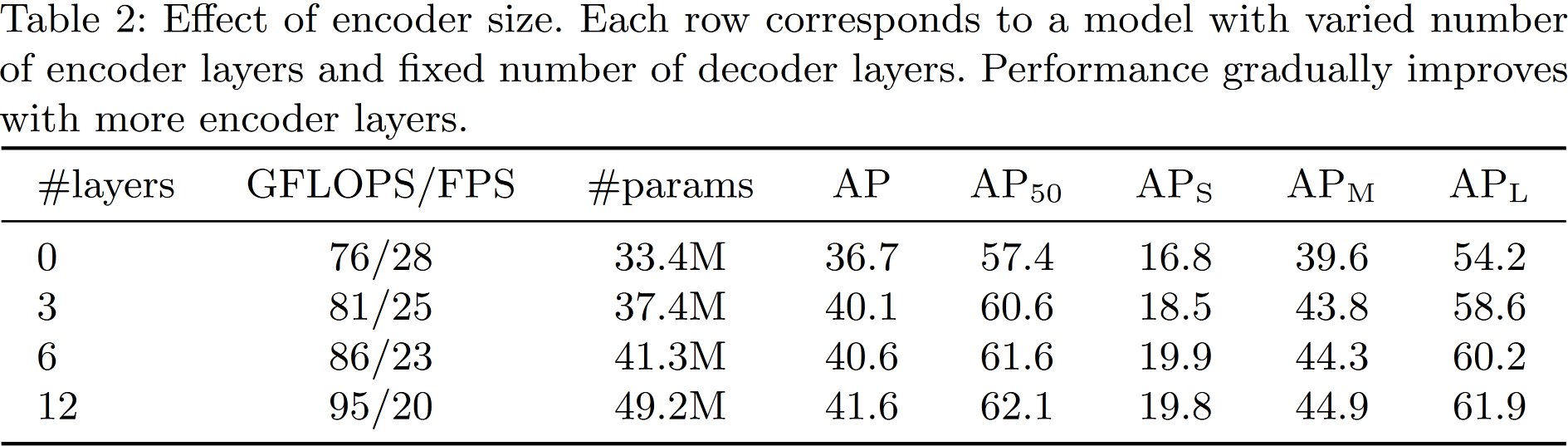
4.2 Ablations

4.3 DETR for panoptic segmentation