Paper | CLIP 笔记 & 系列论文串烧
1. CLIP 笔记
1.1 TL;DR
1.2 方法
直接上图1:
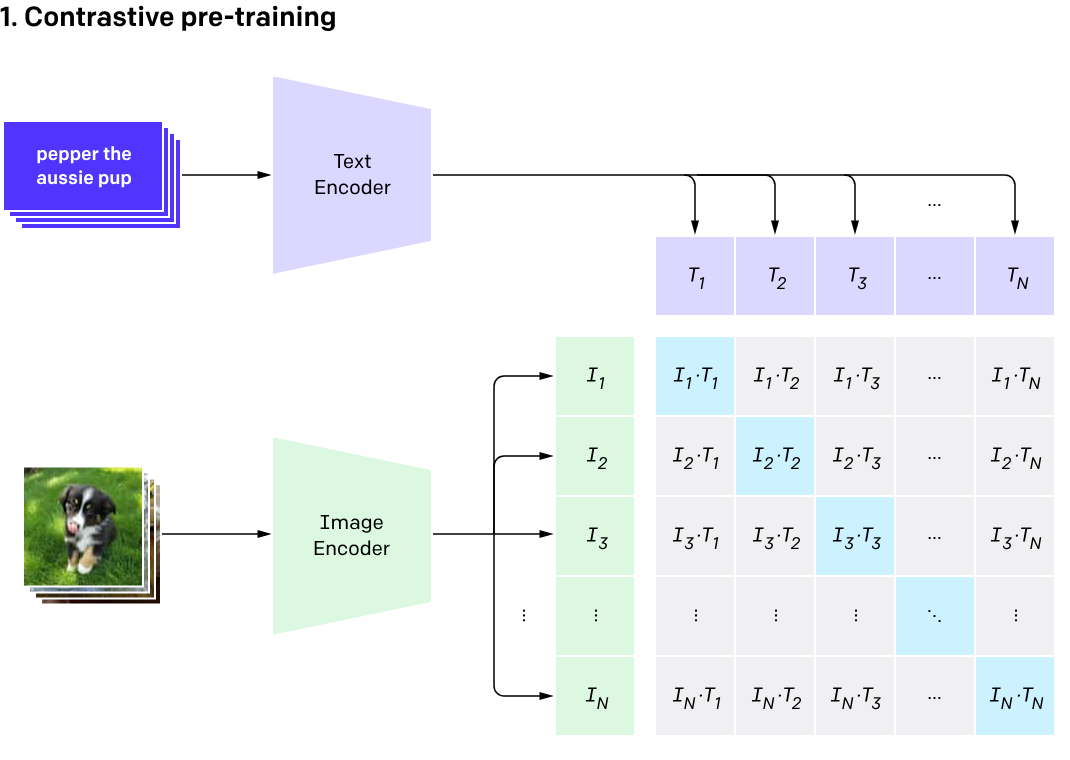
CLIP 这个模型的结构很简单,甚至是简单粗暴,但很有用。模型由一个图像编码器和一个文本编码器组成,图像编码器可以使用 ResNet 或者 ViT,文本编码器可以使用 Transformer。二者的编码输出通过对比学习进行对齐,然后进行训练就好了。论文中还给出了该模型的伪代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# extract feature representations of each modality
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# joint multimodal embedding [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# scaled pairwise cosine similarities [n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# symmetric loss function
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2
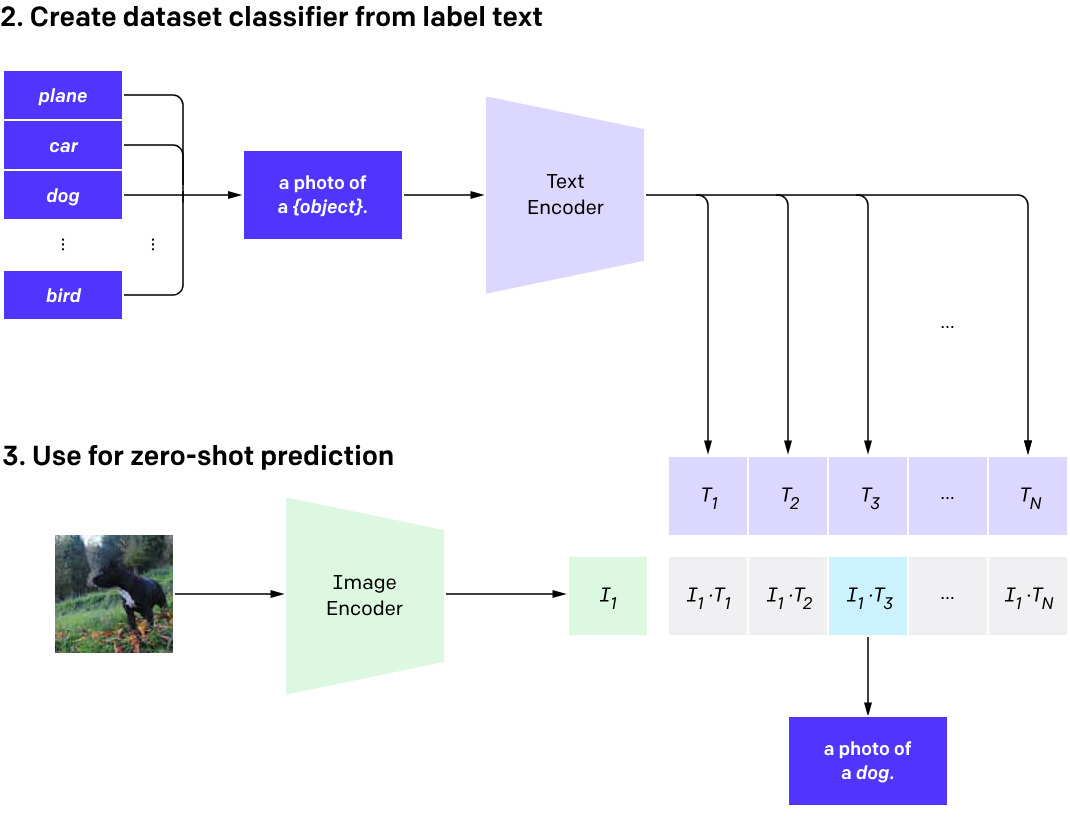
在预测的时候,由于 CLIP 只是通过对比学习将学到的图像特征与文本特征进行点积选择最大值对应的文本。所以在进行分类任务时,还需要进行 Prompt Engineering,例如 ImageNet 中的 1000 个类,作者设计了一个 prompt template:a photo of a {label},然后将生成的 1000 个句子的文本特征与图像特征进行比较,得到最终的分类结果(见上图的第 2、3 步)
实际上因为标签可能会有多义性(比如有一种狗是“boxer”),在不同的上下文会带有不同的语义信息,所以文中 CLIP 在分类时有多个 prompt template 以供选择:
作者为了达到良好的训练效果,还专门从网上收集了 4 亿个图片-文本对(只能说财大气粗)从头开始学习。最后从 30 个数据集上的实验结果上来看,CLIP 的对比学习真的是又简单又好用,能够有效地提取图片的语义信息,同时发现 CLIP 的 zero-shot 能力非常好,在 ImageNet 上零样本分类的准确性要高于经过有监督学习过的 ResNet-50。
1.3 优缺点
1.3.1 优点
- 使用对比学习的方式进行训练,计算简单高效,使得模型的收敛速度快
- 文本标签不再是一个独立的词,而是一个句子。这使得模型能够更好地提取图片中的多层次语义信息,同时让 CLIP 可以迁移到很多不同的下游任务上,比如 OCR、动作识别、地理定位等
1.3.2 缺点
- 文中提到的 4 亿个图片-文本对数据集并未公开。训练的数据集非常大,而在测试时使用的数据集比如 ImageNet 要比这个训练集数量上少几个量级
- CLIP 对一些细粒度的分类任务还是力不从心,比如区分汽车型号、花卉种类等
- 展示结果时的结果是针对测试进行调参后得到的,zero-shot 能力有所夸大
2. 改进工作
CLIP 这个模型确实太好用了,以至于很快涌现出了一些相关的工作,下面挑了一些论文2简单解释了一下:
2.1 LSeg
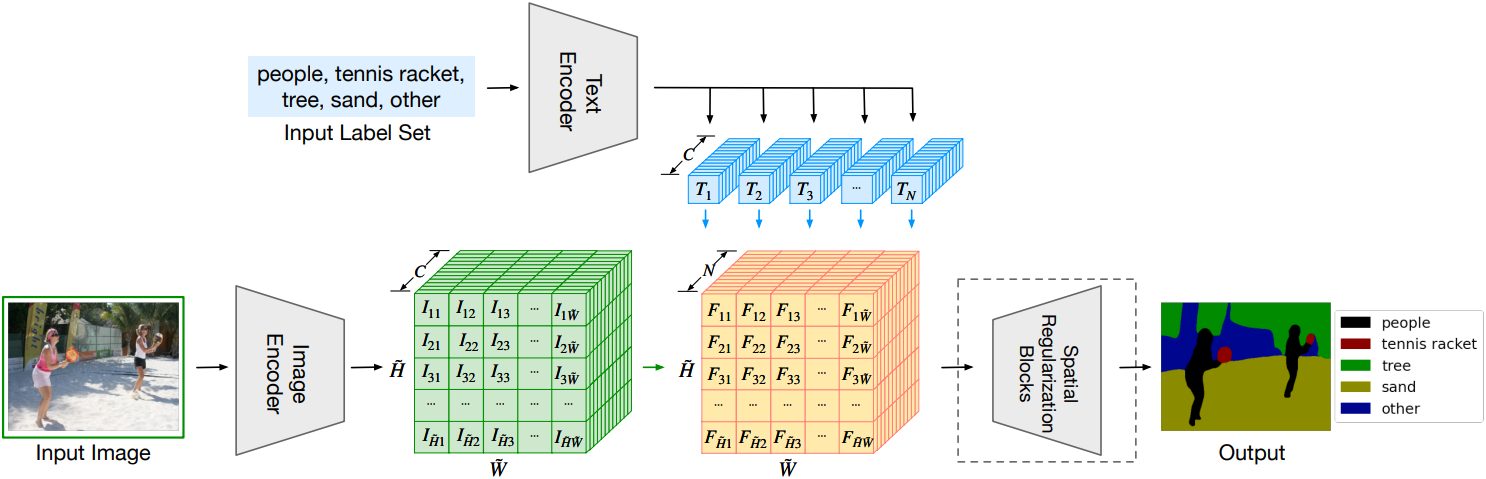
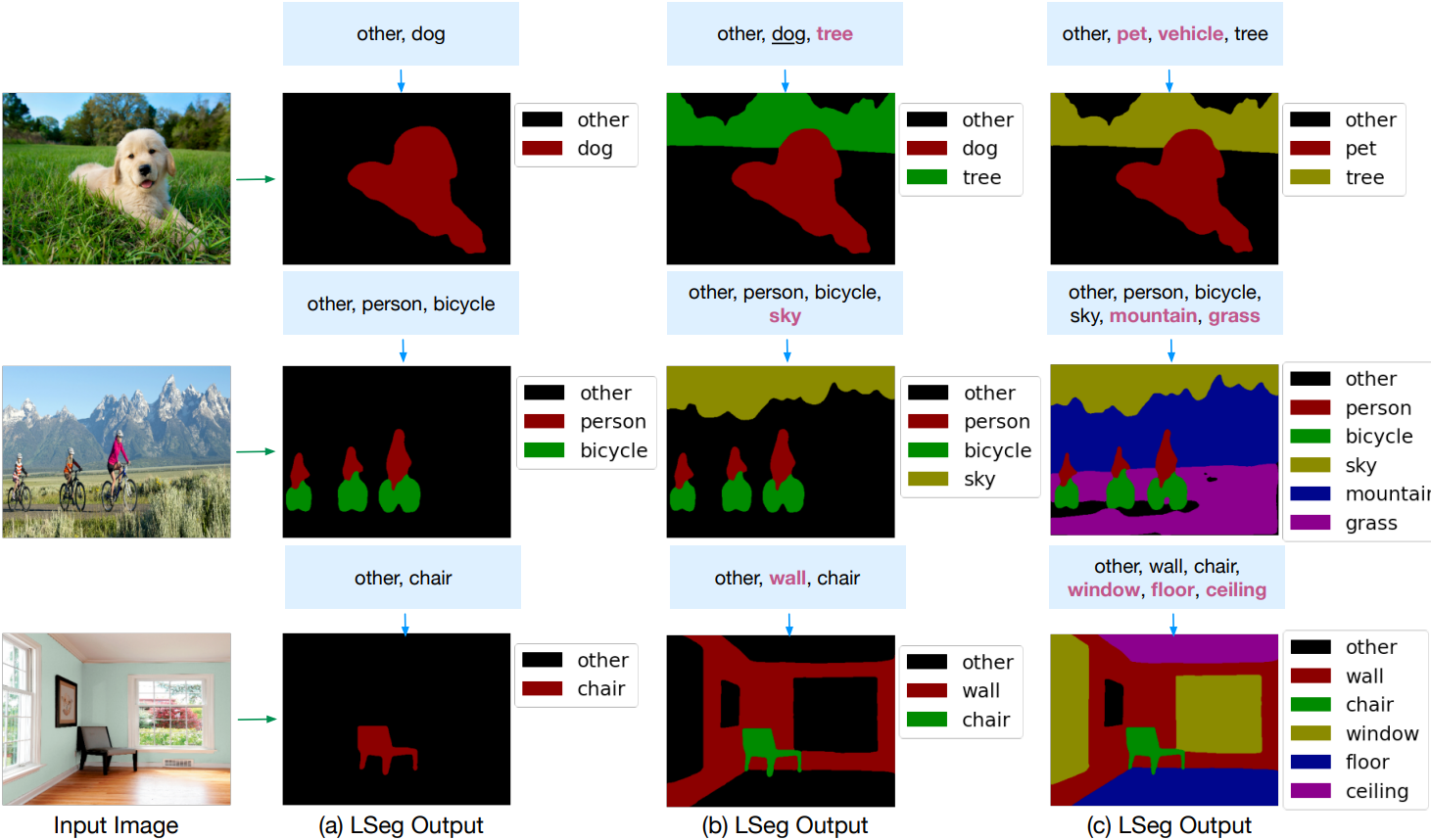
LSeg 是一种新颖的语言驱动的语义图像分割模型。它利用文本编码器和基于 Transformer 的图像编码器对输入的描述性标签和图像进行嵌入计算。通过对比度训练,图像编码器将像素嵌入与相应语义类别的文本嵌入对齐。文本嵌入提供了灵活的标签表示,使得相似语义的标签在嵌入空间中映射到相似的区域。这使得 LSeg 能够在测试时推广到以前未见过的类别,而无需重新训练或额外的训练样本
2.2 GroupViT
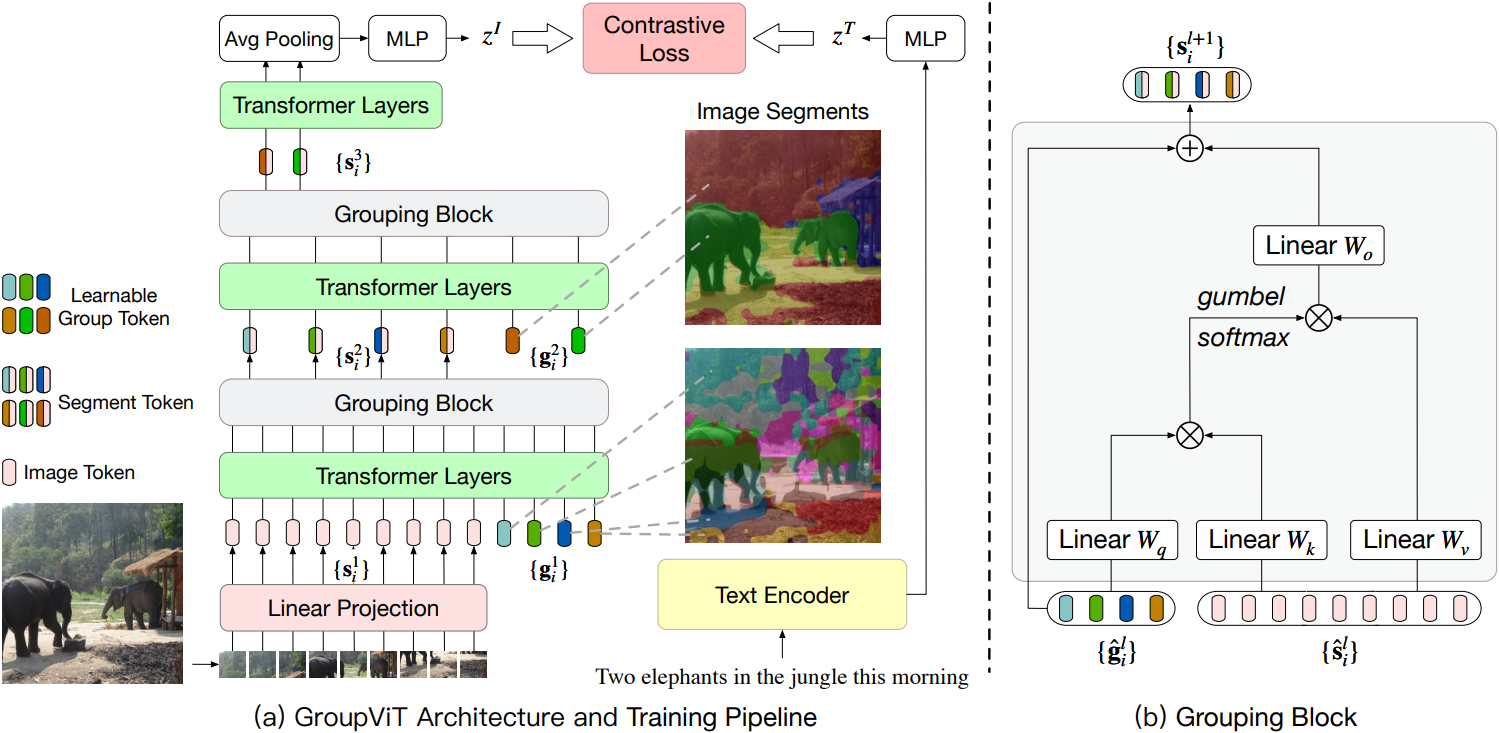
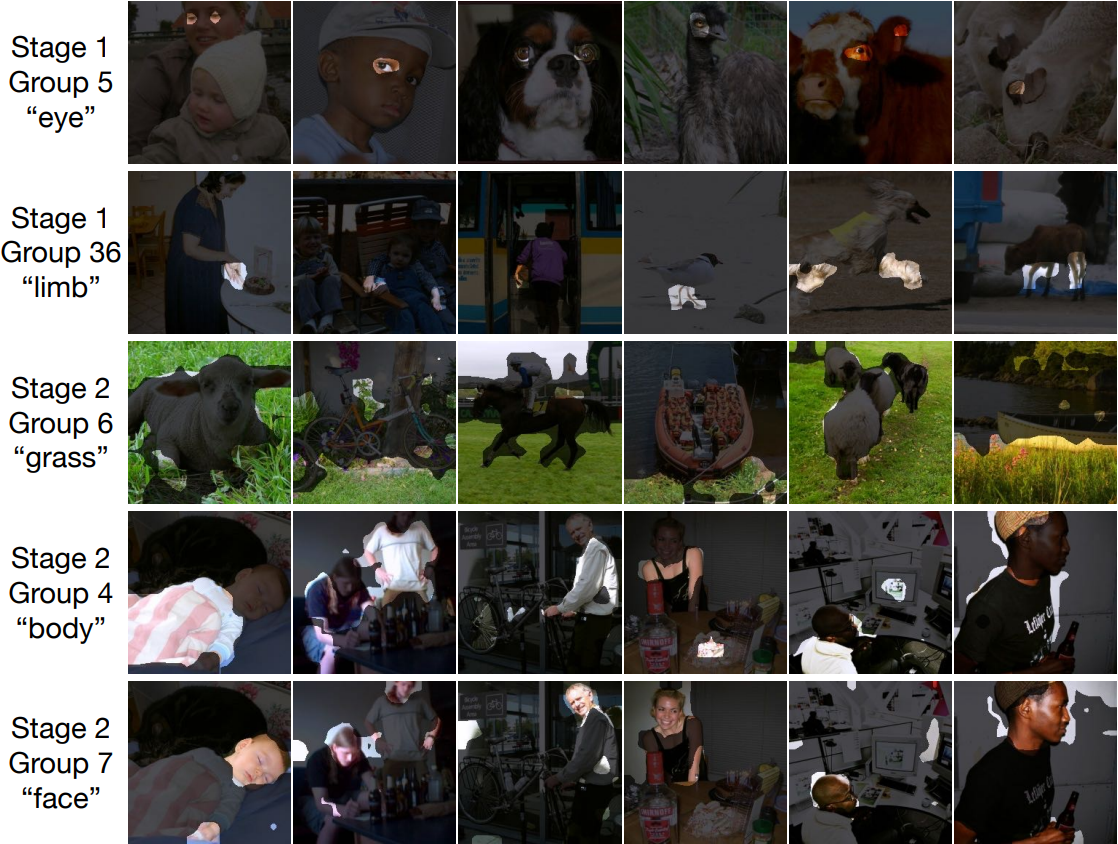
视觉场景理解的重要组成部分是分组和识别,例如目标检测和语义分割。在端到端的深度学习系统中,图像区域的分组通常是通过自顶向下的监督来隐式进行的,这是通过像素级别的识别标签来实现的。然而,在本文中,作者提出将分组机制重新引入深度网络中,这允许语义分段仅通过文本监督自动出现。文章提出了一种分层分组视觉 Transformer(GroupViT),它超越了常规的网格结构表示,并学会将图像区域分组成逐渐变大的任意形状的段。作者通过对比损失在大规模图像文本数据集上联合训练 GroupViT 和文本编码器。只通过文本监督,没有任何像素级注释,GroupViT 学会将语义区域分组在一起,并成功地以零样本的方式转移到语义分割任务,即无需进一步微调
2.3 ViLD
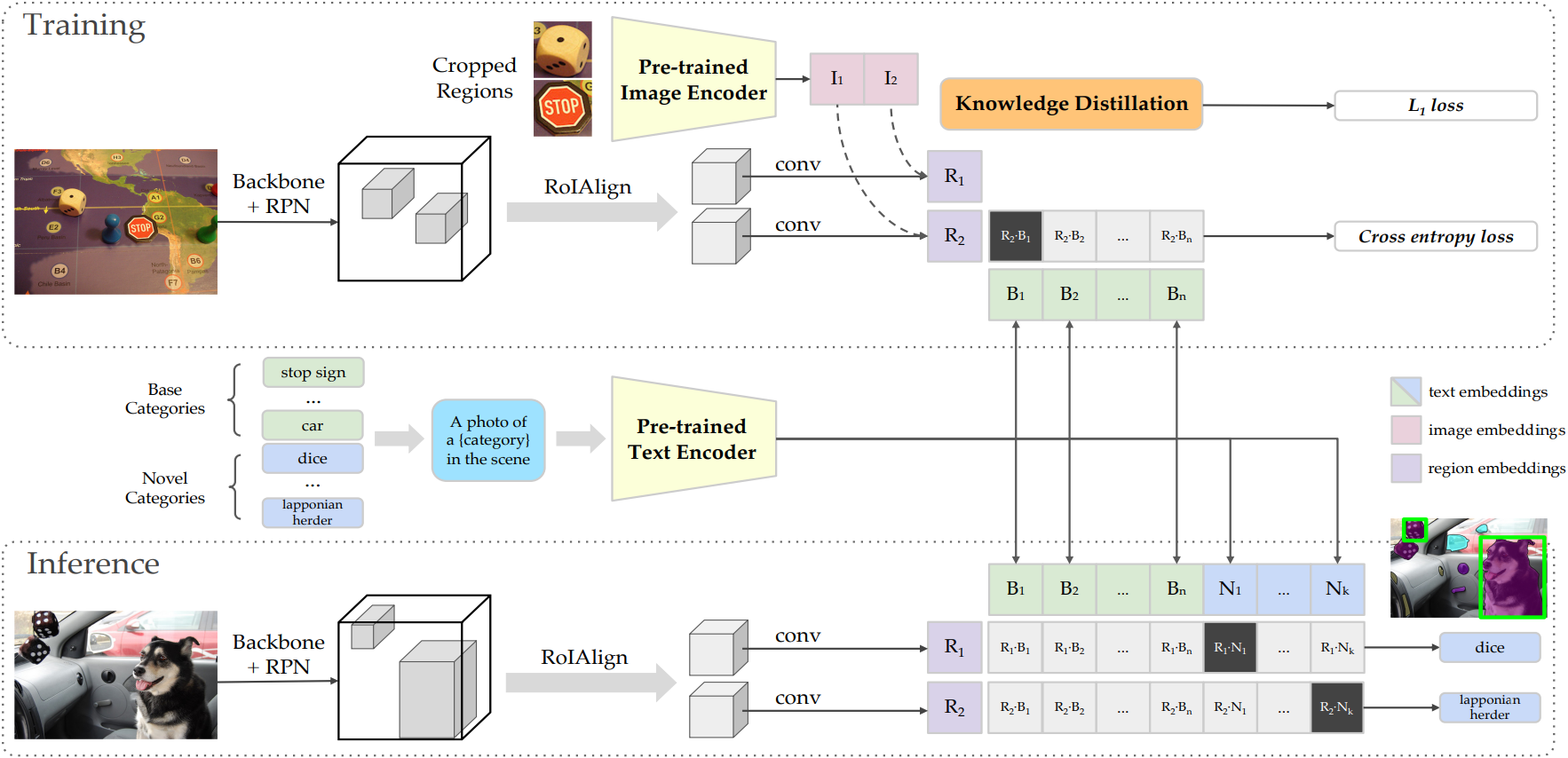
本文的目标是推进开放词汇的目标检测,即检测由任意文本输入描述的对象。根本挑战是训练数据的可用性。进一步扩大现有目标检测数据集中包含的类别数量是昂贵的。为了克服这个挑战,本文提出了 ViLD,一种通过视觉和语言知识蒸馏的训练方法。文章的方法将预训练的开放词汇图像分类模型(教师模型)的知识蒸馏到一个两阶段检测器(学生模型)中。具体而言,作者使用教师模型对目标提案的类别文本和图像区域进行编码。然后,作者训练一个学生检测器,其检测到的框的区域嵌入与教师模型推断的文本和图像嵌入对齐

2.4 GLIP
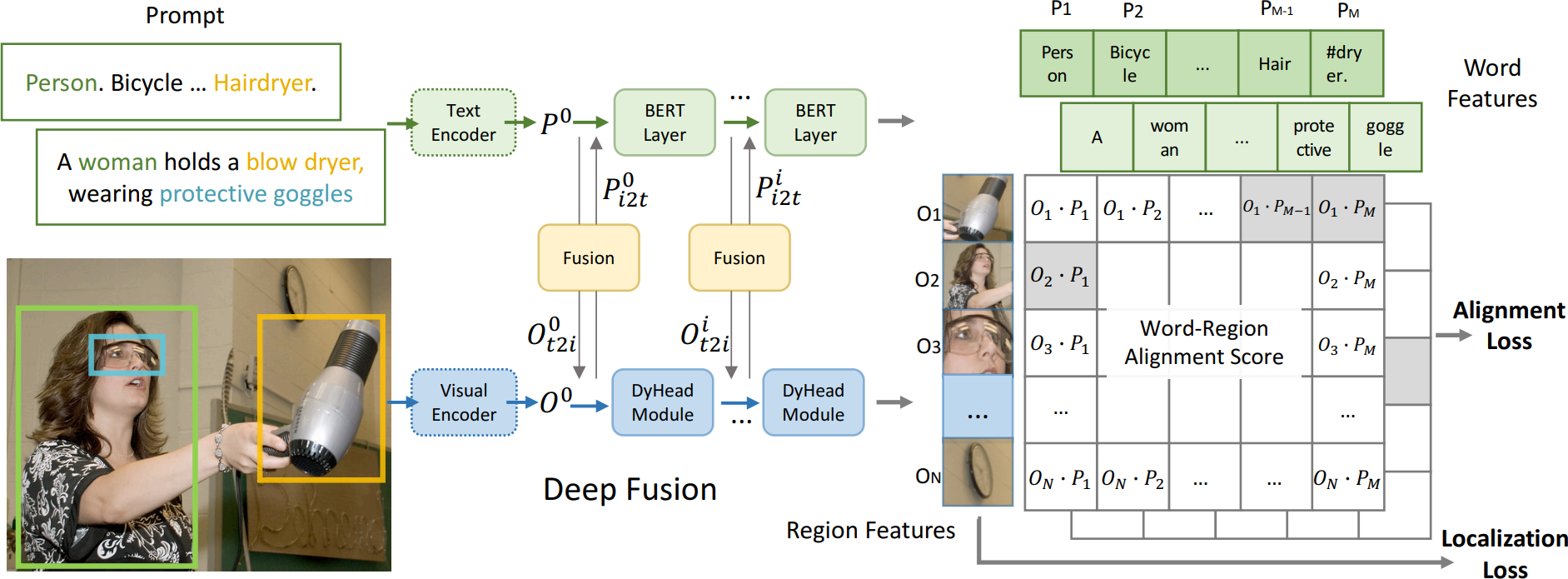
本文提出了一种基于语言-图像的预训练(GLIP)模型,用于学习对象级、语言感知和语义丰富的视觉表示。GLIP 统一了目标检测和短语定位的预训练。这种统一带来了两个好处:
- 它允许 GLIP 从检测和定位数据中学习,以改进这两个任务并启动一个良好的定位模型
- GLIP 可以通过自我训练的方式利用大量的图像文本对,生成定位框,使学到的表示具有丰富的语义
在实验中,作者在 2700 万个定位数据上对 GLIP 进行了预训练,包括 300 万个人工注释和 2400 万个网络抓取的图像文本对。学到的表示展现出对各种对象级识别任务的强零样本和少样本可迁移性

2.5 CLIPasso
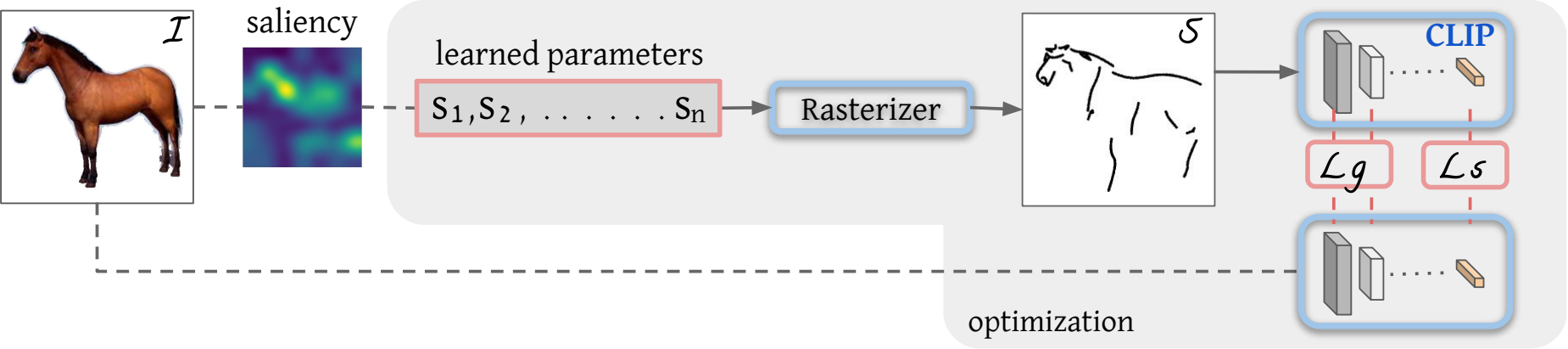
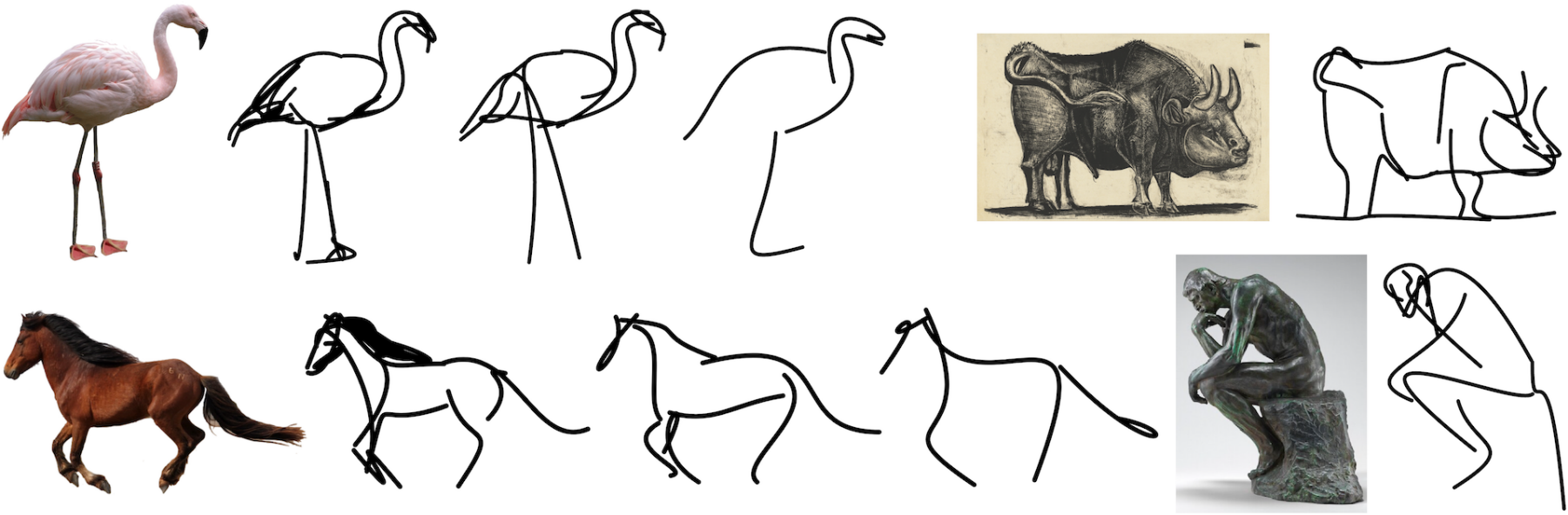
抽象是素描的核心,因为线条画作的简单和简约性质。抽象涉及识别物体或场景的基本视觉属性,这需要语义理解和对高级概念的先验知识。对于艺术家来说,抽象描绘是具有挑战性的,对于机器来说更是如此。本文提出了 CLIPasso,一种可以通过几何和语义简化来实现不同抽象层次的物体素描方法。虽然素描生成方法通常依赖于显式的素描数据集进行训练,但文章利用了 CLIP(对比-语言-图像-预训练)的非凡能力,可以从素描和图像中提取语义概念。作者将素描定义为一组贝塞尔曲线,并使用可微分的光栅化器来直接优化曲线参数,以使其与基于 CLIP 的感知损失相对应。抽象程度通过改变笔画数量来控制。生成的素描展示了多个抽象层次,同时保持了可识别性、基本结构和被绘制主体的重要视觉组成部分
2.6 CLIP4clip
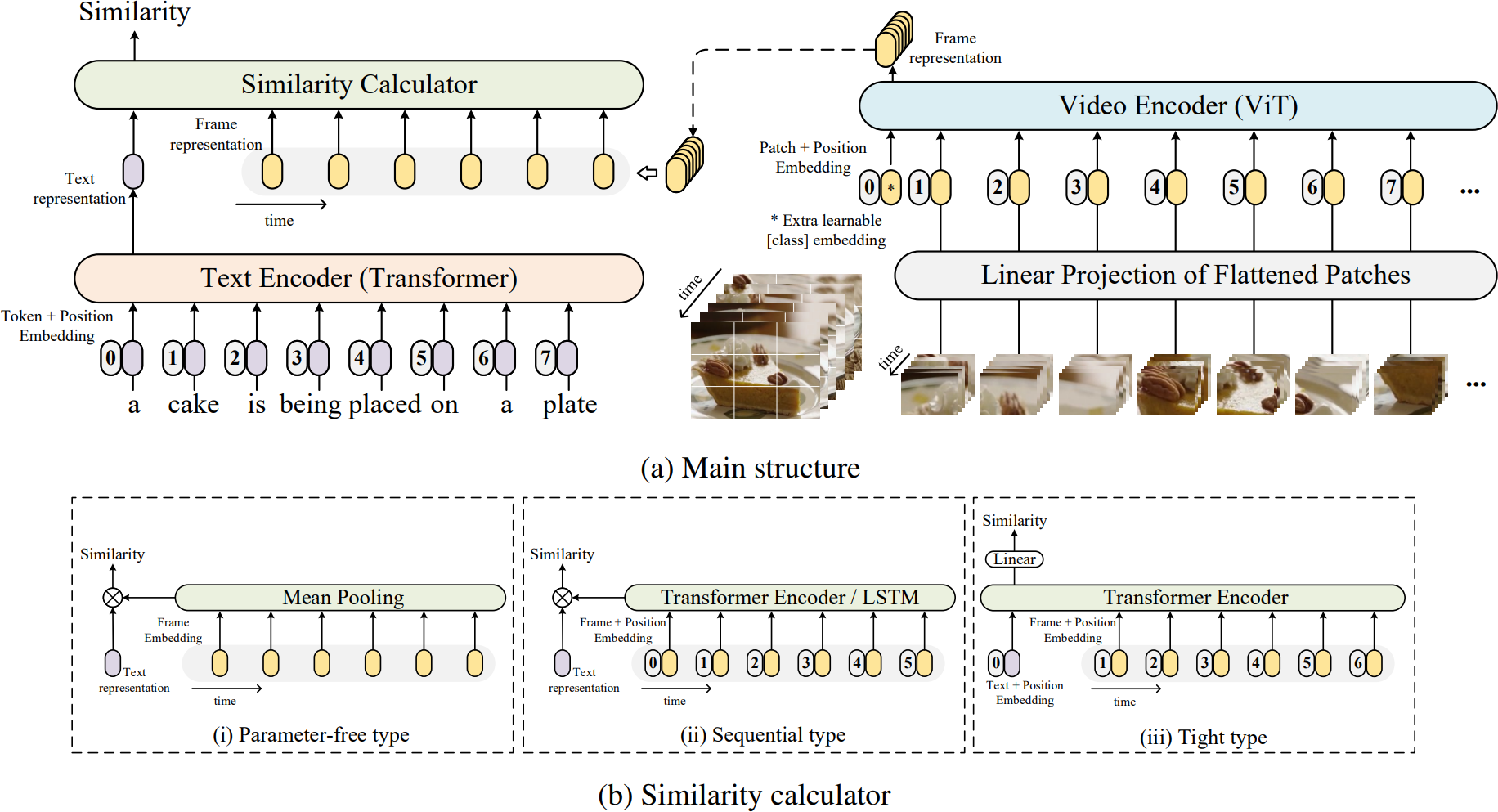
视频文本检索在多模态研究中扮演着重要角色,并在许多实际的网络应用中被广泛使用。CLIP 是一种图像-语言预训练模型,展示了从网络收集的图像-文本数据集中学习视觉概念的能力。在这篇论文中,作者提出了一个名为 CLIP4Clip 的模型,以端到端的方式将 CLIP 模型的知识转移到视频-语言检索中。通过经验研究探讨了几个问题:
- 图像特征是否足够用于视频-文本检索?
- 基于 CLIP 进行大规模视频-文本数据集的后预训练如何影响性能?
- 建模视频帧之间的时间依赖的实际机制是什么?
- 模型在视频-文本检索任务中的超参数敏感性
2.7 Action CLIP
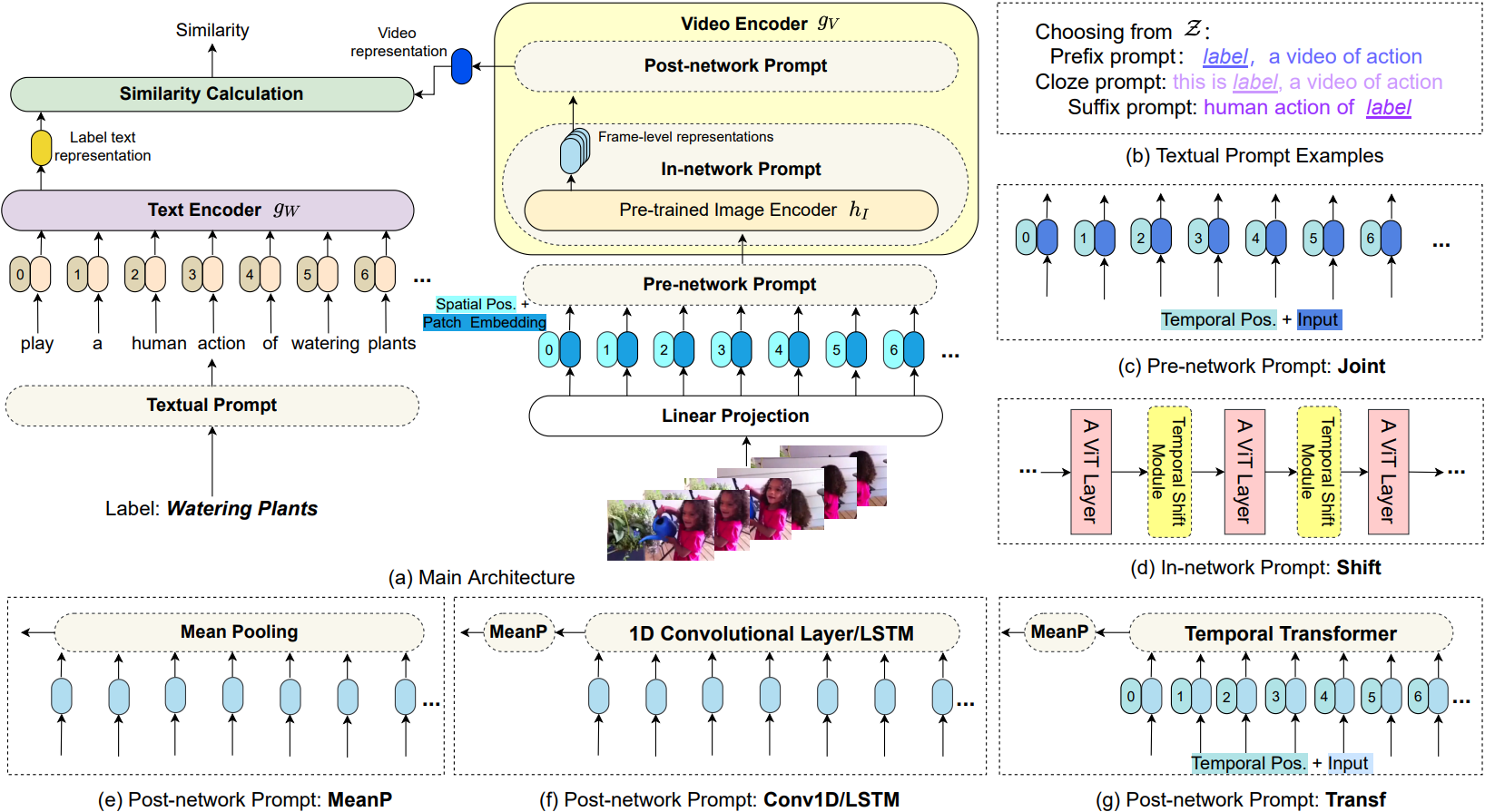
视频动作识别的经典方法要求神经模型执行经典和标准的 1 对 N 多数投票任务。它们被训练来预测一组预定义的固定类别,从而限制了它们在新数据集上对未知概念的可转移能力。在本文中提出了一种新的动作识别视角,强调标签文本的语义信息,而不仅仅是将它们简单地映射为数字。具体而言,文章将这个任务建模为一个视频文本匹配问题,融入了多模态学习框架,通过更多的语义语言监督来增强视频表示,并使本文的模型能够在没有进一步标记数据或参数要求的情况下进行零样本动作识别。此外,为了处理标签文本的不足并利用大量的网络数据,文章提出了一个基于这个多模态学习框架的动作识别新范式,称之为“预训练、提示和微调”。这个范式首先通过在大量网络图像-文本或视频-文本数据上进行预训练来学习强大的表示。然后,通过 prompt engineering,使动作识别任务更像是预训练问题。最后,它在目标数据集上进行端到端的微调,以获得强大的性能。本文给出了这个新范式的一个实例,ActionCLIP,它不仅具有卓越且灵活的零样本/少样本转移能力,而且在一般动作识别任务上达到了最佳性能
2.8 CLIP-ViL
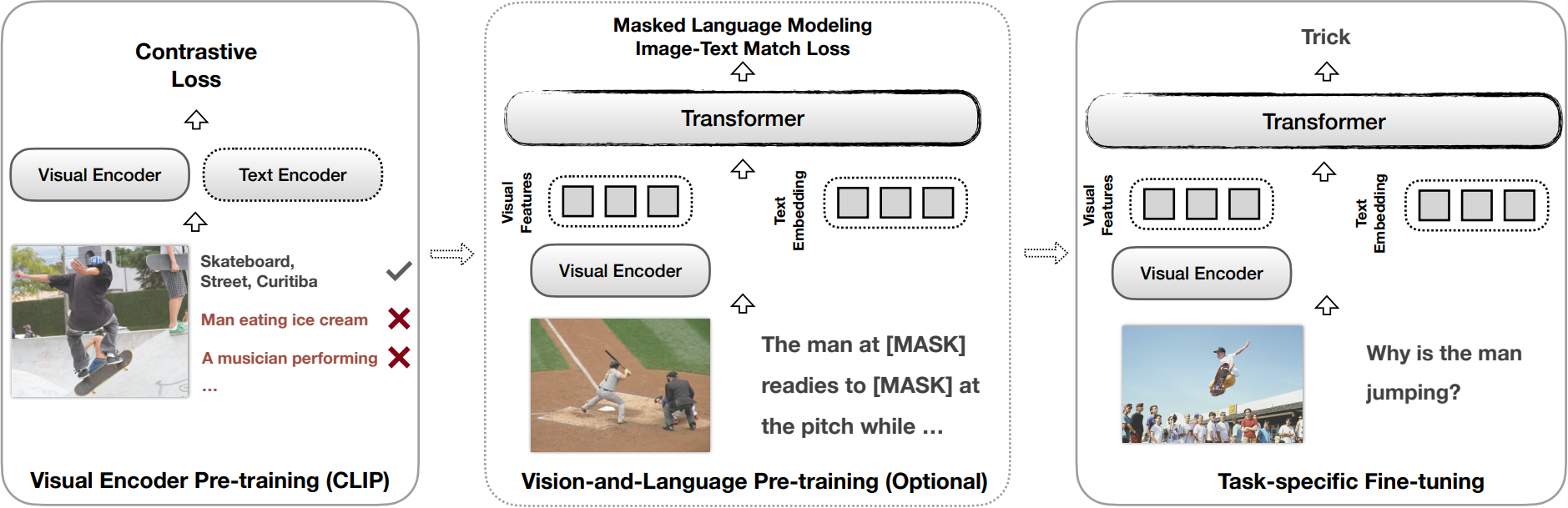
大多数现有的视觉与语言(V&L)模型依赖于预先训练的视觉编码器,使用相对较小的手工注释数据(与网络抓取的数据相比)来感知视觉世界。然而,已经观察到,大规模的预训练通常会导致更好的泛化性能,例如,CLIP 在大量图像标题对上进行训练,表现出在各种视觉任务上强大的零样本能力。为了进一步研究 CLIP 带来的优势,本文提出在两种典型场景中将 CLIP 用作各种 V&L 模型的视觉编码器:
- 将 CLIP 插入到特定任务的微调中
- 将 CLIP 与 V&L 预训练相结合,并将其转移到下游任务
文章表明,CLIP 在各种 V&L 任务上明显优于使用领域内注释数据训练的广泛使用的视觉编码器,如 BottomUp-TopDown。本文在多样的 V&L 任务上取得了竞争性或更好的结果,同时在视觉问题回答、视觉蕴涵和 V&L 导航任务上建立了新的最先进结果
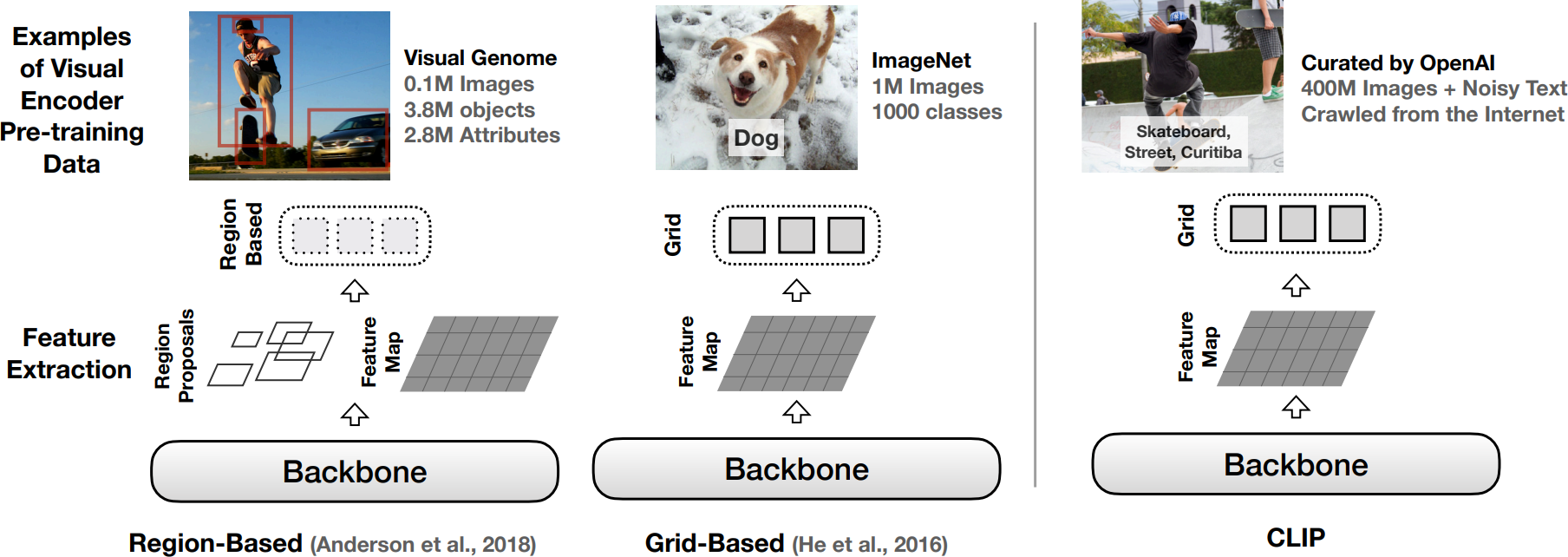
2.9 AudioCLIP
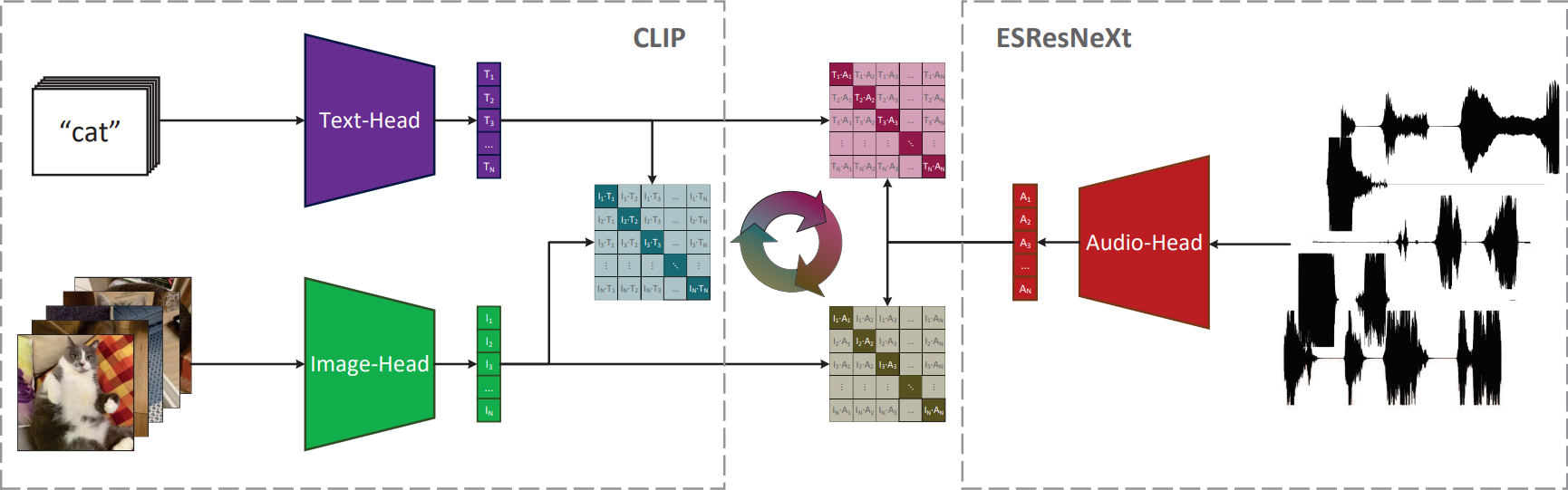
在过去,声音分类领域的快速发展极大地受益于其他领域方法的应用。如今,文章作者观察到融合领域特定任务和方法的趋势,为社区提供了新的出色模型。在这项工作中,本文提出了 CLIP 模型的扩展,除了文本和图像外,还处理音频。本文的模型将 ESResNeXt 音频模型与 CLIP 框架结合,使用 AudioSet 数据集。这种组合使得所提出的模型能够执行双模式和单模式分类和查询,同时保持了 CLIP 在零样本推理方式下对未知数据集的泛化能力
2.10 PointCLIP
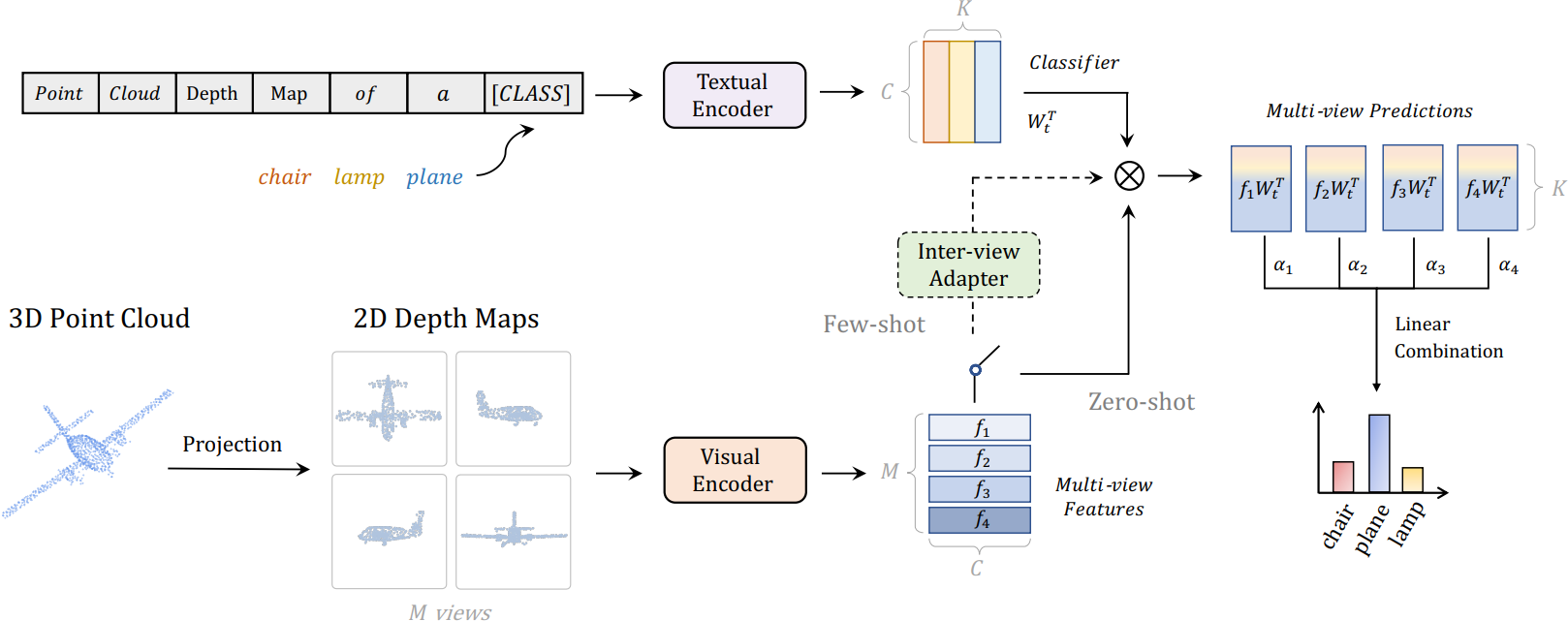
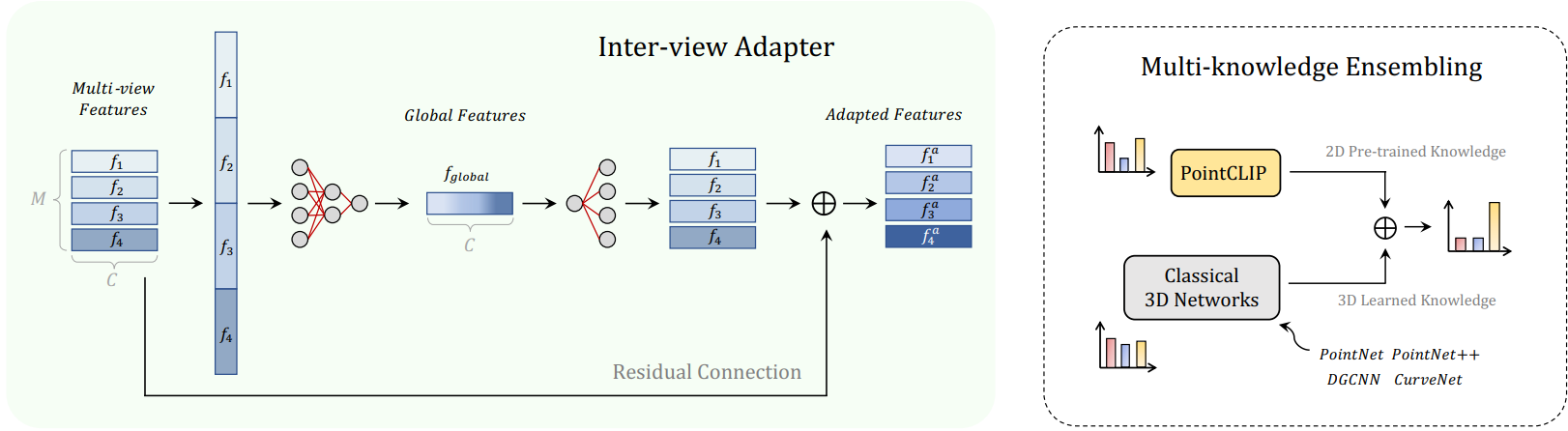
最近,通过对比视觉-语言预训练(CLIP)进行的零样本和少样本学习,在 2D 视觉识别方面展现出了令人鼓舞的性能。CLIP 在开放词汇环境中学习将图像与相应的文本进行匹配。然而,目前尚未探索 CLIP 在 2D 大规模图像-文本对训练下是否可以推广到 3D 识别。在本文中,作者通过提出 PointCLIP 来证明这种情况是可行的,PointCLIP 通过对齐 CLIP 编码的点云和 3D 类别文本进行操作。具体而言,文章通过将点云投影到多视角深度图中(无需渲染)对其进行编码,并聚合视角级的零样本预测,实现从 2D 到 3D 的知识转移。此外,本文设计了一个视角间适配器,以更好地提取全局特征,并将从 3D 学习的少样本知识自适应地融合到在 2D 中预训练的 CLIP 中。通过在少样本设置中仅微调轻量级适配器,可以大大提高 PointCLIP 的性能。此外,作者观察到 PointCLIP 与传统的 3D 监督网络之间的互补性质。通过简单的集成,PointCLIP 提升了基线模型的性能,甚至超过了最先进的模型。因此,PointCLIP 是一种具有潜力的替代方案,可以在低资源成本和数据环境下有效理解 3D 点云
2.11 DepthCLIP
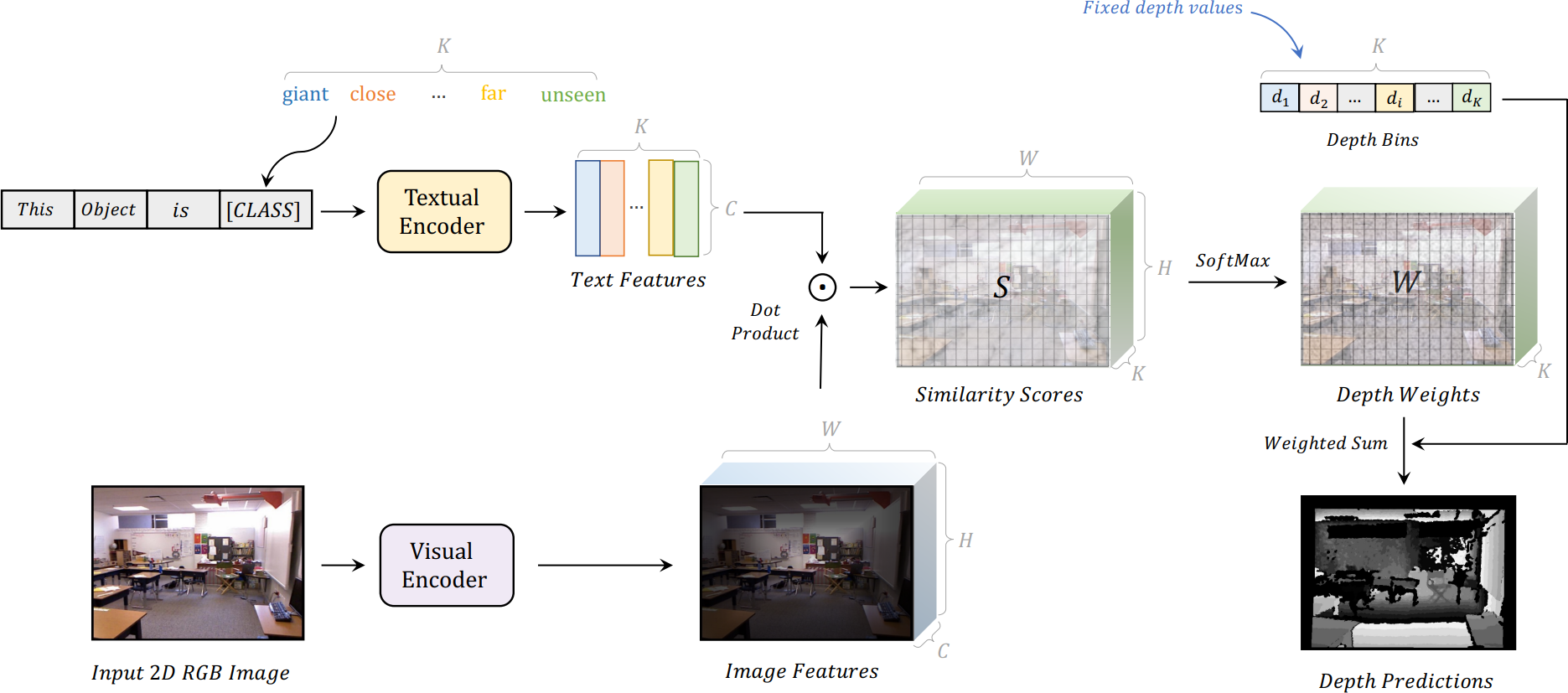
除了图像分类,对比语言-图像预训练(CLIP)在包括物体级和3D空间理解在内的各种视觉任务中取得了非凡的成功。然而,将从 CLIP 中学到的语义知识转移到更复杂的定量目标任务中仍然具有挑战性,例如具有几何信息的深度估计。在本文中,作者提出了将 CLIP 应用于零样本单目深度估计的方法,称为 DepthCLIP。文章发现输入图像的补丁可以对特定的语义距离标记做出响应,然后投影到量化的深度区间进行粗略估计。在没有任何训练的情况下,DepthCLIP 超过了现有的无监督方法,甚至接近了早期的全监督网络。据作者所知,他们是第一个从语义语言知识到定量下游任务进行零样本适应并进行零样本单目深度估计的研究。作者希望他们的工作能为未来的研究提供启示
