NavGPT:使用大模型进行视觉和语言导航的显示推理模型
- NavGPT: Explicit Reasoning in Vision-and-Language Navigation with Large Language Models
- 论文地址:https://arxiv.org/abs/2305.16986
摘要
在以前所未有的数据规模进行训练的情况下,像 ChatGPT 和 GPT-4 这样的大型语言模型(LLMs)展现出了模型规模扩展带来的重要推理能力的出现。这种趋势突显了使用无限语言数据训练 LLMs 的潜力,推动了通用体验智能代理的发展。在这项工作中,本文介绍了 NavGPT,一种纯粹基于 LLM 的指令遵循导航代理器,通过进行零样本顺序动作预测来揭示 GPT 模型在复杂的实体场景中的推理能力,用于视觉语言导航(VLN)。在每个步骤中,NavGPT 将视觉观察的文本描述、导航历史记录和未来可探索方向作为输入,推理代理器的当前状态,并做出接近目标的决策。通过全面的实验,本文证明 NavGPT 能够明确地执行导航的高级规划,包括将指令分解为子目标、整合与导航任务相关的常识知识、从观察到的场景中识别地标、跟踪导航进展以及通过调整计划适应异常情况。此外,本文展示了 LLMs 能够根据路径上的观察和动作生成高质量的导航指令,以及根据代理器的导航历史绘制准确的自顶向下度量轨迹。尽管使用 NavGPT 进行零样本 R2R 任务的性能仍然不及经过训练的模型,但本文建议为 LLMs 适应多模态输入以用作视觉导航代理,并将 LLMs 的明确推理应用于受益于基于学习的模型。
论文贡献
- 引入了一种新颖的指令遵循 LLMs 代理器,用于视觉导航,配备一个支持系统与环境进行交互,并追踪导航历史记录
- 研究了当前 LLMs 在进行导航决策时的能力和局限性
- 揭示了 LLMs 在导航的高级规划方面的能力,通过观察LLMs的思维,使导航代理器的规划过程可访问和可解释
相关工作
略
方法
VLN 问题描述:给定一个自然语言指令 $\mathcal{W}$,由一系列单词 ${w_1,w_2,\cdots,w_n}$ 组成,在每个步骤 $s_t$ 中,代理器通过模拟器解释当前位置,以获取一个观察结果 $\mathcal{O}$。这个观察结果包括 N 个备选视角,表示不同方向上的代理器的自我中心视角。其中,每一个视角可表示为 $o_i(i\leqslant N)$,与之相关的角度和方向可表示为 $a_i(i\leqslant N)$。于是观察结果可被定义为:
\[\mathcal{O}_t=[<o_1,a_1>,<o_2,a_2>,\cdots,<o_N,a_N>]\]| 在整个导航过程中,代理的动作空间被限制在导航图 $G$ 中。代理必须从 $M=\lvert C_{t+1}\rvert$ 个可导航视点中进行选择,将观察结果 $\mathcal{O}t^C=[<o_1^C,a_1^C>,<o_2^C,a_2^C>,\cdots,<o_M^C,a_M^C>]$ 与标准指令 $W$ 对齐,这里 $C{t+1}$ 表示候选视角集合。代理通过选择与 $\mathcal{O}i^C$ 的相对角度 $a_i^C$ 来预测后续动作,然后通过与模拟器的交互来执行此动作,从当前状态 $s_t=<v_t,\theta_t,\phi_t>$ 到状态 $s{t+1}=<v_{t+1},\theta_{t+1},\phi_{t+1}>$。代理还维护历史状态记录 $h_t$,并调整状态之间的条件转移概率 $\mathcal{S}t=T(s{t+1} | a_i^C,s_t,h_t)$,其中 $T$ 表示条件转移的概率分布。 |
| 综上所述,代理需要学习的由 $\Theta$ 参数化的策略 $\pi$ 是基于预测机 $\mathcal{W}$ 和当前的观测值 $\mathcal{O}_t^C$ 得出的,即 $\pi(a_t | \mathcal{W},\mathcal{O}_t,\mathcal{O}_t^C,\mathcal{S}_t;\Theta)$。在本文的研究中,NavGPT 以零样本的方式执行 VLN任务,其中 $\Theta$ 并不会从 VLN数据集中进行学习,而是从 LLM 训练的语言语料库中进行学习。 |
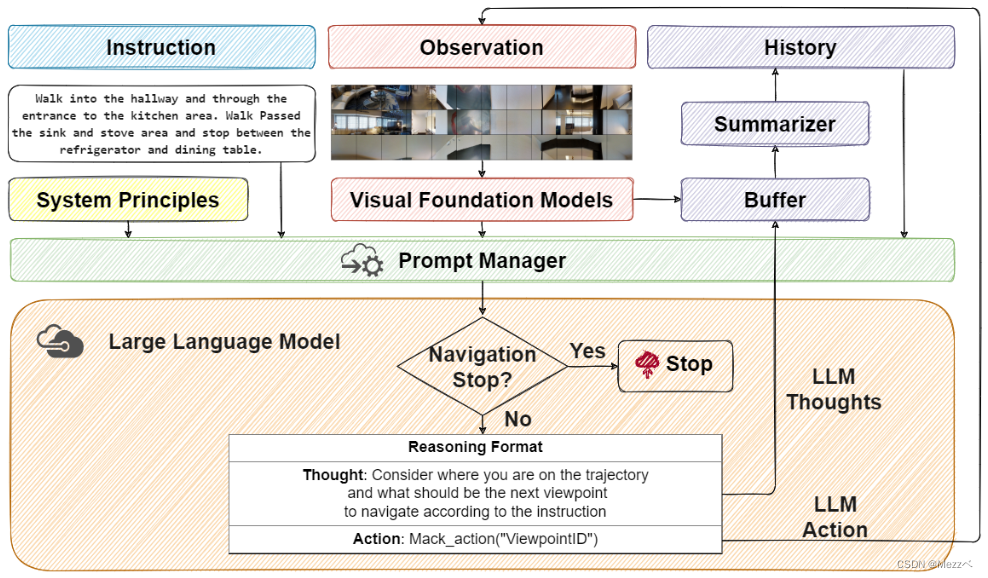
NavGPT
NavGPT 是一个通过与环境、语言引导和导航历史交互来执行动作预测的算法模型。将前 $t$ 步的观察 $\mathcal{O}$、LLM 推理 $\mathcal{R}$ 和动作 $\mathcal{A}$ 三元组的导航历史设为
\[\mathcal{H}_{<t+1}=[<\mathcal{O}_1,\mathcal{R}_1,\mathcal{A}_1>,<\mathcal{O}_2,\mathcal{R}_2,\mathcal{A}_2>,\cdots<\mathcal{O}_t,\mathcal{R}_t,\mathcal{A}_t>]\]为了获得导航决策 $A_{t+1}$,NavGPT需要在提示管理器 $\mathcal{M}$ 的帮助下,将来自 VFMs $\mathcal{F}$ 的视觉感知、语言指令 $\mathcal{W}$、历史 $\mathcal{H}$ 和导航系统原则 $\mathcal{P}$ 进行协同作用,定义如下:
\[<\mathcal{R}_{t+1},\mathcal{A}_{t+1}>=LLM(\mathcal{M}(\mathcal{P}),\mathcal{M}(\mathcal{W}),\mathcal{M}(\mathcal{F}(\mathcal{O}_t)),\mathcal{M}(\mathcal{H}_{<t+1}))\]- 导航系统原则 $\mathcal{P}$:导航系统原则指定了 LLM 作为 VLN 的代理。明确定义了 VLN 的任务和 NavGPT 在每个导航步骤的基本推理格式和规则。例如,NavGPT 应该通过识别唯一的视点 ID 在预定义环境图的静态视点(位置)之间移动。 NavGPT 不应伪造不存在的 ID
- 视觉基础模型 $\mathcal{F}$:NavGPT 作为 LLM 代理需要 VFM 的视觉感知和表达能力,将当前环境的视觉观察转化为自然语言描述。VFMs 在这里扮演翻译的角色,用它们自己的语言翻译视觉观察,例如自然语言、对象的边界框和对象的深度。通过对 Prompt 的管理,视觉感知结果将被重新转化为纯自然语言以供 LLM 理解
- 导航历史 $\mathcal{H}{<t+1}$:导航历史对于 NavGPT 评估指令完成进度、更新当前状态以及做出后续决策至关重要。历史由对先前的观察 $\mathcal{O}{<t+1}$ 和动作 $\mathcal{A}{<t+1}$ 的总结描述以及来自 LLM 的推理 $\mathcal{R}{<t+1}$ 组成
- Prompt 管理 $\mathcal{M}$:使用 LLM 作为 VLN 代理的关键是将上述所有内容转换成 LLM 可以理解的自然语言。这个过程由 Prompt 管理器完成,它从不同的组件收集结果并将它们解析为单个提示,供 LLM 做出导航决策