MIT 6.5840 | Lab1: MapReduce
分布式学习中绕不开的一门经典公开课 —— MIT 6.824
- 官网链接:https://pdos.csail.mit.edu/6.824/labs/lab-mr.html
- MapReduce 论文:https://research.google.com/archive/mapreduce-osdi04.pdf
论文解读
首先还是来读一读论文,搞清楚 MapReduce 的实现细节,在后面的代码实现中不至于抓瞎
印象:什么是 MapReduce?
首先建立一个整体的印象:MapReduce 是一种用于处理海量数据的分布式编程模型,核心思想是将复杂任务拆解成两个阶段(Map 和 Reduce),通过分而治之并行处理数据。它最早由 Google 提出,后来成为大数据领域的基石技术之一
想象让 100 个人数一屋子里的书:
- Map:每人负责一个书架,记录每本书名(生成局部列表)
- Shuffle:把相同书名的记录纸条收拢到不同篮子
- Reduce:每个篮子由专人统计总数,最终汇总结果
这种分工方式比一个人数全屋快无数倍,这正是 MapReduce 的核心价值
背景:海量数据处理要解决哪些问题?
作者在谷歌工作,工作期间接触了大量海量计算的场景,需要对大量的原始数据(爬取的文档、网页请求日志等)进行处理,以生成各类衍生数据,比如倒排索引、网页文档图等表示、每主机爬取页面数的汇总,以及特定日期内最频繁查询的集合等。大多数此类计算在概念上是直观的,但输入数据通常规模庞大,必须分布到数百或数千台机器上才能在合理时间内完成。想要解决这些困难,则需克服如下挑战:
- 如何设计算法使其可以并行计算?
- 各类数据如何在机器间分发?
- 机器或计算出现故障时如何进行处理?
为了应对这些难题,作者团队受 Lisp 以及其他函数式语言中 map 和 reduce 原语的启发,提出了 MapReduce 这一算法
案例:MapReduce 经典使用场景
- 分布式 Grep
-
问题:在大规模文档中查找匹配特定模式的行。
- Map:若输入行匹配模式,输出该行。
- Reduce:将中间数据原样复制到输出(恒等函数)。
- 输出:所有匹配模式的行。
- Map:若输入行匹配模式,输出该行。
- URL 访问频率统计
-
问题:统计每个 URL 的访问次数。
- Map:处理日志,输出
<URL, 1>。- Reduce:累加同一 URL 的计数值,输出
<URL, 总访问次数>。- 输出:每个 URL 的总访问次数。
- Map:处理日志,输出
- 反向网络链接图
-
问题:构建网页链接关系图(目标 → 来源)。
- Map:提取网页中的链接,输出
<target, source>。- Reduce:合并同一目标的所有来源,输出
<target, [source列表]>。- 输出:每个目标 URL 对应的来源列表。
- Map:提取网页中的链接,输出
- 每主机词向量
-
问题:统计每个主机下文档的高频词。
- Map:提取文档主机名和词向量,输出
<hostname, term_vector>。- Reduce:合并同一主机的词向量,过滤低频词,输出
<hostname, merged_vector>。- 输出:每个主机的合并词向量。
- Map:提取文档主机名和词向量,输出
- 倒排索引
-
问题:构建单词到文档 ID 的映射表。
- Map:解析文档,输出
<word, doc_id>。- Reduce:排序同一单词的文档 ID,输出
<word, [doc_id列表]>。- 输出:每个单词对应的文档 ID 列表。
- Map:解析文档,输出
- 分布式排序
-
问题:对大规模数据进行排序。
- Map:提取记录的键,输出
<key, record>。- Reduce:原样输出键值对(依赖分区和排序属性)。
- 输出:按键排序的记录集合。
- Map:提取记录的键,输出
实现:MapReduce 背后的机理
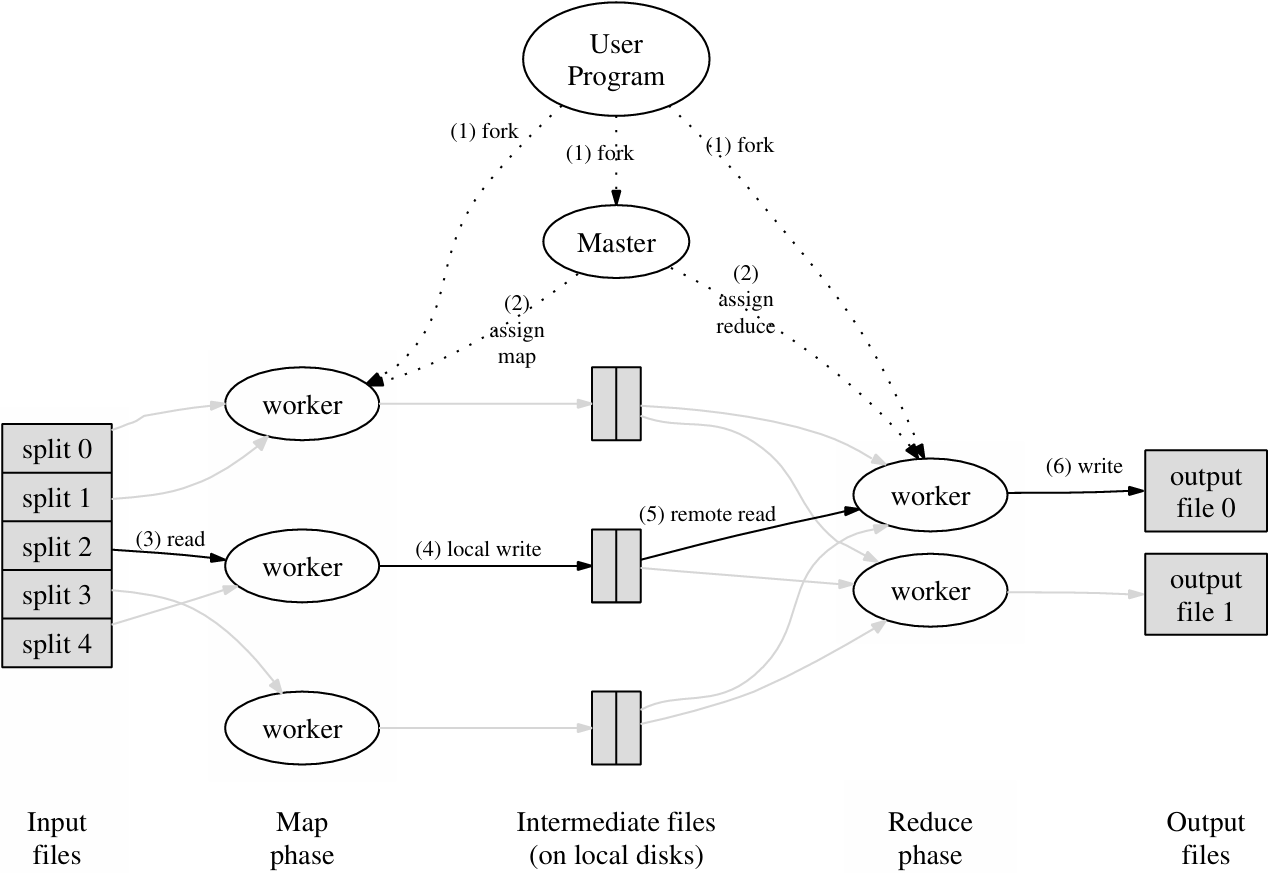
整体执行流程
1. 输入文件分割
- MapReduce 库将输入文件分割成 M 个分片,每个分片大小通常为 16 - 64MB,可由用户通过可选参数控制。
- 在集群多台机器上启动程序的多个副本。
2. 主节点与任务分配
- 程序副本中有一个主节点(master),其余为工作节点(worker)。
- 主节点负责分配任务,共有 M 个 Map 任务和 R 个 Reduce 任务。
- 主节点挑选空闲工作节点,为其分配 Map 或 Reduce 任务。
3. Map 任务执行
- 被分配 Map 任务的工作节点读取对应输入分片内容。
- 从输入数据中解析键值对,传递给用户定义的 Map 函数。
- Map 函数生成的中间键值对缓冲到内存。
4. 中间数据写入磁盘
- 缓冲的键值对定期写入本地磁盘,通过分区函数划分为 R 个区域。
- 工作节点将本地磁盘上中间数据的位置信息传回主节点。
- 主节点将位置信息转发给 Reduce 工作节点。
5. Reduce 任务读取与排序
- Reduce 工作节点通过远程过程调用从 Map 工作节点本地磁盘读取中间数据。
- 读取完所有中间数据后,按中间键排序,使相同键的出现情况分组。
- 若中间数据量太大无法装入内存,使用外部排序。
6. Reduce 函数执行
- Reduce 工作节点遍历排序后的中间数据。
- 对于每个唯一中间键,将键和对应中间值组传递给用户的 Reduce 函数。
- Reduce 函数的输出追加到该 Reduce 分区的最终输出文件。
7. 任务完成与返回
- 所有 Map 任务和 Reduce 任务完成后,主节点唤醒用户程序。
- MapReduce 调用返回到用户代码。
输出结果
- 成功完成后,输出保存在 R 个输出文件中(每个 Reduce 任务对应一个),文件名由用户指定。
- 用户通常无需合并文件,可将其作为输入用于其他 MapReduce 调用或分布式应用。
Master 节点数据结构
主节点维护着多个数据结构。对于每个Map任务和Reduce任务,主节点存储以下信息:
- 任务状态(空闲、进行中或已完成);
- 工作机器标识(针对非空闲任务)。
主节点作为中间文件区域位置信息从Map任务传递到Reduce任务的渠道。具体来说:
- 对于每个已完成的Map任务,主节点会存储该任务生成的R个中间文件区域的位置和大小。
- 随着Map任务的完成,主节点会接收这些位置和大小信息的更新。
- 这些信息会被逐步推送给正在执行的Reduce任务的工作节点,以确保它们能及时获取最新的数据位置。
容错机制解析
一、Worker 节点故障处理
-
心跳检测机制
- 主节点周期性向所有 Worker 发送心跳请求。
- 若某个 Worker 在指定时间内无响应,主节点将其标记为 失败。
-
任务状态重置
- Map 任务:已完成的任务因输出存储在本地磁盘,需重新执行。
- Reduce 任务:已完成的任务因输出在全局文件系统,无需重执行。
- 进行中的任务:无论 Map 或 Reduce,均重置为空闲状态,重新调度。
-
数据重定向
- 当 Map 任务在另一 Worker 重新执行时,所有正在处理的 Reduce 节点会被通知新的中间数据位置。
- 未读取旧数据的 Reduce 节点将自动从新 Worker 获取数据。
-
大规模故障案例
- 曾在集群网络维护中,同时失去 80 台机器的连接。
- 主节点通过重执行这些机器的任务,最终成功完成计算。
二、Master 节点故障处
-
检查点机制
- 主节点定期将关键数据结构(如任务状态、中间文件位置)写入磁盘。
- 若 Master 崩溃,可从最后一个检查点恢复。
-
当前实现限制
- 因 Master 是单点,其故障会导致整个任务终止。
- 用户需手动重试任务(客户端可检测并自动重试)。
三、故障下的语义保证
-
确定性操作的原子性
- Map 任务:输出写入临时文件,完成后向主节点提交文件名。
- Reduce 任务:输出通过原子重命名操作写入最终文件。
- 结果保证:即使任务重执行,最终文件仅保留最后一次成功提交的结果。
-
非确定性操作的处理
- 若 Map/Reduce 函数为非确定性,不同 Reduce 任务可能读取不同 Map 输出版本。
- 但每个 Reduce 任务的输出仍等价于顺序执行的某个可能结果。
-
示例说明
- 假设 Map 任务 M 被重执行,Reduce 任务 R1 可能读取 M 的第一次输出,R2 读取第二次输出。
- 最终结果等价于顺序执行中不同分支的组合。
备份任务
延长 MapReduce 操作总耗时的常见原因之一是 “拖后腿任务”(straggler):即某台机器在完成计算中最后几个 Map 或 Reduce 任务时异常缓慢。拖后腿任务可能由多种原因导致:
- 硬件问题:如磁盘损坏导致频繁可纠正错误,使读取速度从 30 MB/s 降至 1 MB/s。
- 资源竞争:集群调度系统在该机器上安排了其他任务,导致 CPU、内存、本地磁盘或网络带宽竞争,降低 MapReduce 代码执行速度。
- 软件 bug:例如机器初始化代码中的错误导致处理器缓存被禁用,受影响机器的计算速度减慢 100 倍以上。
文章设计了一种通用机制缓解拖后腿问题:当 MapReduce 操作接近完成时,主节点会为剩余进行中的任务调度备份执行。无论主任务还是备份任务先完成,该任务即被标记为完成。此机制的优化目标是将操作消耗的计算资源增加控制在 几个百分点以内。
实践表明,这显著减少了大型 MapReduce 操作的完成时间。例如,第 5.3 节提到的排序程序在禁用备份任务机制时,完成时间会延长 44%。
细化:核心改进与高级特性
分区与排序优化
-
自定义分区函数
- 默认使用
hash(key) mod R分区,确保负载均衡。 - 扩展场景:
1 2 3 4
// 示例:按主机名分区 URL partition(urlkey) { return hash(hostname(urlkey)) % R; }
- 默认使用
-
全局排序保证
- 每个分区内的中间键值对按升序处理,确保输出文件有序。
- 应用价值:支持高效随机访问(如数据库索引构建)。
性能增强机制
-
合并器函数(Combiner)
- 作用:在 Map 节点本地合并重复键值,减少网络传输。
- 示例:
1 2 3 4 5
combiner(word, counts) { sum = 0; for (count in counts) sum += count; emit(word, sum); // 本地合并后再发送 }
- 效果:单词计数任务可减少 90% 的网络数据量。
-
数据局部性优化
- 优先将 Map 任务调度到存储输入数据的节点,节省带宽。
- 实现:结合 GFS 数据分布与网络位置感知调度。
容错与调试
-
跳过坏记录
-
机制:
- 捕获段错误信号,记录崩溃记录序列号。
- 主节点检测重复失败后跳过该记录。
- 适用场景:第三方库不可修复的 bug 或大数据集统计。
-
机制:
-
本地执行模式
- 功能:在单台机器上模拟分布式执行,支持断点调试。
- 使用方式:
1
./program --local # 启动本地模式
元数据与监控
-
状态监控页面
- 实时指标:任务进度、输入/输出量、处理速率。
- 诊断信息:失败节点及任务日志链接。
- 访问方式:通过主节点 HTTP 服务(默认端口 50070)。
-
计数器(Counters)
- 自定义统计:
1 2 3 4
Counter* german_docs = GetCounter("german_docs"); map(doc) { if (doc.language == "de") german_docs->Increment(); }
- 内置指标:输入/输出键值对数量、任务重试次数。
扩展能力
-
灵活的输入输出
- 支持格式:文本、数据库、内存映射。
- 扩展方式:实现简单的 Reader/Writer 接口。
-
副作用管理
- 原子性保证:临时文件 + 原子重命名。
- 限制:多文件一致性需由用户确保(通过确定性操作)。
最佳实践建议
- 性能优化:尽可能使用合并器函数,减少网络 I/O。
- 容错设计:在不可靠环境中启用备份任务与坏记录跳过。
- 监控策略:通过计数器验证业务逻辑,结合状态页面定位性能瓶颈。
通过这些改进,MapReduce 在保持编程模型简洁的同时,实现了对复杂分布式环境的强大适应能力。
实验说明
你的任务是实现一个分布式MapReduce系统,包含两个程序:协调器(Coordinator)和工作进程(Worker)。系统中只有一个协调器进程,但可以有多个工作进程并行执行。实际系统中工作进程可能分布在不同机器上,但本实验中所有进程均在单台机器运行。工作进程通过RPC与协调器通信。每个工作进程会循环向协调器请求任务,读取任务输入文件,执行任务,写入输出文件,然后再次请求新任务。协调器需检测工作进程是否在合理时间内(本实验设定为10秒)未完成任务,并将任务重新分配给其他工作进程。
代码结构
- 协调器和工作进程的主程序已提供,分别位于
main/mrcoordinator.go和main/mrworker.go,请勿修改这两个文件。 - 你的实现应放在以下文件中:
-
mr/coordinator.go(协调器逻辑) -
mr/worker.go(工作进程逻辑) -
mr/rpc.go(RPC接口定义)
-
运行示例(词频统计)
-
编译MapReduce插件:
1
$ go build -buildmode=plugin ../mrapps/wc.go
-
启动协调器:
1 2
$ rm mr-out* $ go run mrcoordinator.go pg-*.txt
-
pg-*.txt为输入文件,每个文件对应一个Map任务。
-
-
启动工作进程:
1
$ go run mrworker.go wc.so -
验证输出:
1 2 3 4 5
$ cat mr-out-* | sort | more A 509 ABOUT 2 ACT 8 ...
测试脚本
我们提供了测试脚本test-mr.sh,用于验证以下功能:
- 词频统计(wc)
- 索引器(indexer)
- Map并行处理
- Reduce并行处理
- 任务计数
- 提前退出
- 崩溃恢复
当前测试状态
如果现在运行测试脚本,会因协调器无法完成而挂起:
1
2
3
$ cd ~/6.5840/src/main
$ bash test-mr.sh
*** Starting wc test.
临时修改
为快速验证,可将mr/coordinator.go中的Done函数返回值改为true:
1
2
3
4
5
func (c *Coordinator) Done() bool {
// ret := false
ret := true // 临时修改
return ret
}
修改后测试结果如下(任务未实际执行):
1
2
3
4
5
6
$ bash test-mr.sh
*** Starting wc test.
sort: No such file or directory
cmp: EOF on mr-wc-all
--- wc output is not the same as mr-correct-wc.txt
--- wc test: FAIL
预期测试结果
完成实验后,测试脚本应输出所有测试通过:
1
2
3
4
5
6
7
$ bash test-mr.sh
*** Starting wc test.
--- wc test: PASS
*** Starting indexer test.
--- indexer test: PASS
...
*** PASSED ALL TESTS
常见错误说明
-
RPC注册警告:
1
2019/12/16 13:27:09 rpc.Register: method "Done" has 1 input parameters; needs exactly three
- 忽略此警告,
Done方法并非通过RPC调用。
- 忽略此警告,
-
连接拒绝错误:
1
2025/02/11 16:21:32 dialing:dial unix /var/tmp/5840-mr-501: connect: connection refused
- 协调器退出后,工作进程尝试连接时可能出现,少量出现属正常现象。
任务核心要求
-
协调器(Coordinator):
- 管理任务分配与状态,检测超时任务并重新分配。
- 通过RPC与工作进程通信,提供任务查询接口。
- 维护Map和Reduce阶段的顺序执行。
-
工作进程(Worker):
- 循环请求任务,执行Map或Reduce操作。
- 使用插件加载用户定义的Map/Reduce函数。
- 处理中间文件的原子性写入和读取。
-
文件格式:
- Map中间文件:
mr-X-Y(X为Map任务号,Y为Reduce任务号)。 - Reduce输出文件:
mr-out-X(X为Reduce任务号),每行格式key value。
- Map中间文件:
实现建议
-
RPC接口设计:
- 在
mr/rpc.go中定义AskForTaskArgs和AskForTaskReply结构体。 - 实现协调器的
AskForTask方法和工作进程的RPC客户端。
- 在
-
状态管理:
- 协调器使用互斥锁保护任务队列和状态信息。
- 工作进程通过原子操作处理文件写入,避免并发冲突。
-
错误处理:
- 协调器通过
time.AfterFunc检测任务超时。 - 工作进程在无法连接协调器时自动退出。
- 协调器通过
一些规则
1. Map阶段的中间键划分
- Map阶段需将中间键划分为
nReduce个桶(nReduce为Reduce任务数,即main/mrcoordinator.go传递给MakeCoordinator()的参数)。 - 每个Map任务需生成
nReduce个中间文件(如mr-X-Y),供后续Reduce任务处理。
2. Reduce输出文件命名
- 第X个Reduce任务的输出文件命名为
mr-out-X。 - 每个
mr-out-X文件包含一行或多行结果,每行格式为key value(使用Go的%v %v格式化)。 -
注意:输出格式需严格与
main/mrsequential.go中注释为”this is the correct format”的代码一致,否则测试脚本将失败。
3. 代码修改范围
-
允许修改:
mr/worker.go、mr/coordinator.go、mr/rpc.go。 - 临时测试限制:可临时修改其他文件测试,但最终需确保代码与原始文件兼容(测试时将使用原始版本)。
4. 中间文件存储位置
- Map任务生成的中间文件需存放在当前目录,以便后续Reduce任务读取。
5. 协调器完成标志
-
mr/coordinator.go需实现Done()方法,当整个MapReduce作业完成时返回true,触发协调器退出。
6. 工作进程退出机制
-
两种实现方式:
-
检测协调器存活:若工作进程无法连接协调器(如
call()失败),可认为协调器已退出(作业完成),工作进程自行终止。 - 伪任务机制:协调器可发送”请退出”的伪任务,通知工作进程结束。
-
检测协调器存活:若工作进程无法连接协调器(如
关键注意事项
-
文件命名:严格遵循
mr-X-Y(Map中间文件)和mr-out-X(Reduce输出文件)的命名规则。 -
格式一致性:输出行格式必须与
mrsequential.go中示例完全一致,否则测试脚本将报错。 - 代码兼容性:确保修改仅针对指定文件,其他文件需与原始版本兼容。
开发调试建议
1. 逐步实现
- 从
mr/worker.go的Worker()函数开始,向协调器发送请求任务的RPC。 - 协调器需返回未启动的Map任务文件名。
- 工作进程读取文件并调用Map函数(参考
mrsequential.go的实现)。
2. 插件机制
-
Map/Reduce函数通过Go插件(
.so文件)动态加载,修改mr/目录后需重新编译插件:1
go build -buildmode=plugin ../mrapps/wc.go
3. 文件系统假设
- 实验假设所有工作进程共享本地文件系统(实际分布式系统需GFS等全局文件系统)。
核心实现步骤
1. 中间文件命名
- 使用
mr-X-Y格式(X为Map任务号,Y为Reduce任务号)。
2. 中间文件存储
-
Map阶段:
-
使用JSON格式序列化键值对:
1 2 3 4
enc := json.NewEncoder(file) for _, kv := range ... { enc.Encode(&kv) }
通过
ihash(key) % nReduce确定Reduce任务编号。
-
-
Reduce阶段:
-
读取所有
mr-X-Y文件,反序列化并排序键值对:1 2 3 4 5 6
dec := json.NewDecoder(file) for { var kv KeyValue if err := dec.Decode(&kv); err != nil { break } kva = append(kva, kv) }
-
3. 输出格式
- Reduce输出文件
mr-out-X需每行格式为key value(与mrsequential.go中一致)。
关键技术细节
1. 并发控制
- 协调器作为RPC服务器,需使用互斥锁保护共享数据(如任务队列)。
2. 超时处理
- 协调器对未完成任务等待10秒后重新分配(假设工作进程崩溃)。
3. 原子文件操作
-
使用临时文件+原子重命名避免部分写入:
1 2 3 4
tempFile, _ := os.CreateTemp("", "mr-tmp-*") defer os.Remove(tempFile.Name()) // 写入数据... os.Rename(tempFile.Name(), "mr-X-Y")
4. 工作进程退出
- 工作进程在无法连接协调器时自行退出(作业完成标志)。
测试与优化
1. 竞态检测
-
使用
go run -race检测并发问题,测试脚本支持此模式:1
GORACE="halt_on_error=1" bash test-mr.sh
2. 崩溃恢复测试
- 使用
mrapps/crash.go插件模拟工作进程随机崩溃。
3. 测试脚本技巧
-
test-mr.sh的输出文件位于mr-tmp/目录。 - 可临时修改脚本在失败后暂停,避免覆盖输出文件。
- 多次运行测试:
bash test-mr-many.sh 100(100次)。
常见陷阱
1. RPC字段命名
- RPC结构体字段必须以大写字母开头,嵌套结构体同理。
2. RPC调用规范
-
调用前确保回复结构体为默认值:
1 2
reply := SomeType{} call("Coordinator.AskForTask", &args, &reply)
3. 任务调度策略
- 避免过度分配备份任务(仅在10秒后触发)。
代码整完了,有时间了再整理吧,先把文章放到这儿,肯定会更新的!