MIT 6.S081 | 0x01 Utilities
这次实验通过几个小的任务让我们熟悉实验的流程以及 xv6 系统的整体概况。从名字可以看出,这次实验只是实现了几个小工具。不过我却花了不少的时间。主要的原因还是对项目结构不熟悉,不清楚怎么开始,看了一些代码,遇到不懂的函数就看看是怎么实现的,结果就是花的时间有点久。不过还好,最后还是把所有任务都做完了
 Boot xv6
Boot xv6
xv6 的代码由 git 管理,需要在 Linux 环境中执行下面的命令获得:
1
git clone git://g.csail.mit.edu/xv6-labs-2020
进入该文件夹后你会发现这里面什么都没有,这是因为每一次的实验都在单独的分支,所以对于这一次的实验,需要转到 util 分支进行
1
git checkout util
现在,文件夹里就多了很多代码,这就是 xv6 的全部代码了(其中还有一些功能可能需要我们以后添加),现在可以尝试运行一下 xv6 系统来检验一下环境是否正常
1
2
3
4
5
6
7
8
9
10
11
$ make qemu
riscv64-unknown-elf-gcc -c -o kernel/entry.o kernel/entry.S
riscv64-unknown-elf-gcc -Wall -Werror -O -fno-omit-frame-pointer -ggdb ...
...
xv6 kernel is booting
hart 2 starting
hart 1 starting
init: starting sh
$
如果能得到与上面类似的结果,那么说明环境没问题。如果跑不起来,那请你看看这里检查一下有什么包没有安装合适
如果要退出 qemu,请先按
Ctrl+A,再按X
sleep
Implement the UNIX program sleep for xv6; your sleep should pause for a user-specified number of ticks. A tick is a notion of time defined by the xv6 kernel, namely the time between two interrupts from the timer chip. Your solution should be in the file
user/sleep.c.
这个任务需要我们实现一个程序 sleep,通过暂停指定的 tick 数来实现,同时题目中也提示这个 tick 是定时器芯片每两次中断之间的间隔。同时提示里还指出要我们使用系统调用 sleep,那就先看看这个系统调用在哪里吧
1
2
3
4
5
6
7
8
// system call
...
char* sbrk(int);
int sleep(int);
int uptime(void);
// ulib.c
...
在 user/user.h 的第 23 行可以看到这个 sleep 系统调用的签名,这个系统调用接受一个 int,返回也是一个 int,然后找了一会儿函数的定义。在整个项目里搜索 sleep 这个单词,最后在 user/usys.pl 里面找到了线索:
1
2
3
4
5
6
7
8
9
10
11
12
13
...
sub entry {
my $name = shift;
print ".global $name\n";
print "${name}:\n";
print " li a7, SYS_${name}\n";
print " ecall\n";
print " ret\n";
}
...
entry("sbrk");
entry("sleep");
entry("uptime");
通过上面的脚本,make qemu 运行后会在 user/usys.S 生成如下的汇编:
1
2
3
4
5
.global sleep
sleep:
li a7, SYS_sleep
ecall
ret
上面这段汇编的意思是将 SYS_sleep 的值存到指定的位置(a7)中,然后使用 ecall 让系统来接管系统调用后续的工作。根据这条线索,找到了 SYS_sleep 的位置在 kernel/syscall.h:14,原来 SYS_sleep 只是一个数,值为 13,这个值在用于 kernel/syscall.c:107 的系统调用表,最终调用的是 sys_sleep 这个函数。这下终于找到了这个系统调用的实现的位置了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
uint64
sys_sleep(void)
{
int n;
uint ticks0;
argint(0, &n);
acquire(&tickslock);
ticks0 = ticks;
while(ticks - ticks0 < n){
if(killed(myproc())){
release(&tickslock);
return -1;
}
sleep(&ticks, &tickslock);
}
release(&tickslock);
return 0;
}
然而读完这个函数,只能知道这个系统调用 int sleep(int) 的输入是一个 tick 数,再就无法获得更多的信息了。所以问题来了,多少个 tick 相当于 1 秒呢?再次使用 ticks 作关键词也没查到有用的信息。我猜测可能在系统初始化的时候有相关的内容。最后,终于在 kernel/start.c:69 看到了直接的答案:
1
2
3
4
5
...
// ask the CLINT for a timer interrupt.
int interval = 1000000; // cycles; about 1/10th second in qemu.
*(uint64*)CLINT_MTIMECMP(id) = *(uint64*)CLINT_MTIME + interval;
...
原来 qemu 中的 1 个 tick 相当于现实世界的 1 秒嘛。这样的话就简单了,下面是这个任务中修改的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
diff --git a/Makefile b/Makefile
index ded5bc2..969397a 100644
--- a/Makefile
+++ b/Makefile
@@ -183,6 +183,7 @@ UPROGS=\
$U/_mkdir\
$U/_rm\
$U/_sh\
+ $U/_sleep\
$U/_stressfs\
$U/_usertests\
$U/_grind\
diff --git a/user/sleep.c b/user/sleep.c
new file mode 100644
index 0000000..052b318
--- /dev/null
+++ b/user/sleep.c
@@ -0,0 +1,19 @@
+#include "kernel/types.h"
+#include "kernel/stat.h"
+#include "user/user.h"
+
+int
+main(int argc, char *argv[])
+{
+ if(argc < 2){
+ fprintf(2, "Usage: sleep seconds\n");
+ exit(1);
+ }
+
+ // see kenel/start.c:69
+ int sec = atoi(argv[1]);
+ int tick = sec * 10;
+ sleep(tick);
+
+ exit(0);
+}
pingpong
Write a program that uses UNIX system calls to “ping-pong” a byte between two processes over a pair of pipes, one for each direction. The parent should send a byte to the child; the child should print “<pid>: received ping”, where <pid> is its process ID, write the byte on the pipe to the parent, and exit; the parent should read the byte from the child, print “<pid>: received pong”, and exit. Your solution should be in the file
user/pingpong.c.
这个任务的目的是让我们熟悉管道的操作。整体的流程为:
- 创建管道,并创建子进程
- 父进程向管道写一个 byte 数据
- 子进程从管道读一个 byte 数据,然后再将其写回去
- 父进程从管道读一个 byte 数据
本任务的代码修改情况如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
diff --git a/Makefile b/Makefile
index 969397a..1c17fe0 100644
--- a/Makefile
+++ b/Makefile
@@ -181,6 +181,7 @@ UPROGS=\
$U/_ln\
$U/_ls\
$U/_mkdir\
+ $U/_pingpong\
$U/_rm\
$U/_sh\
$U/_sleep\
diff --git a/user/pingpong.c b/user/pingpong.c
new file mode 100644
index 0000000..b966cff
--- /dev/null
+++ b/user/pingpong.c
@@ -0,0 +1,34 @@
+#include "kernel/types.h"
+#include "kernel/stat.h"
+#include "user/user.h"
+
+int
+main(int argc, char *argv[])
+{
+ int p[2];
+ char byte = 'a';
+ pipe(p);
+
+ if (fork() == 0) {
+ // child
+ int pid = getpid();
+
+ read(p[0], &byte, 1);
+ printf("%d: received ping\n", pid);
+ close(p[0]);
+ write(p[1], &byte, 1);
+ close(p[1]);
+ } else {
+ // parent
+ int pid = getpid();
+
+ write(p[1], &byte, 1);
+ close(p[1]);
+ read(p[0], &byte, 1);
+ printf("%d: received pong\n", pid);
+ close(p[0]);
+
+ }
+
+ exit(0);
+}
 primes
primes
Write a concurrent version of prime sieve using pipes. This idea is due to Doug McIlroy, inventor of Unix pipes. The picture halfway down this page and the surrounding text explain how to do it. Your solution should be in the file
user/primes.c.
这个任务需要实现一个质数筛,使用的算法倒是很少见,下面是这个算法的示意图:
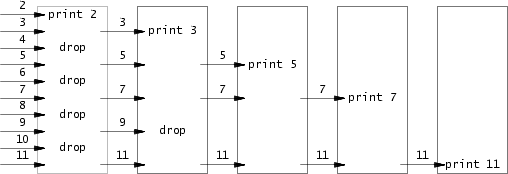
它的伪代码如下
1
2
3
4
5
6
p = get a number from left neighbor
print p
loop:
n = get a number from left neighbor
if (p does not divide n)
send n to right neighbor
根据图示,可以想到将每一个块抽象为一个函数,将左侧的管道作为输入,第一个读到的数一定是质数,然后将其余的数输入到右侧的管道中。因为在提示中只需生成小于 35 的质数,所以在每一个块中可以将左侧管道中读到的数全部存到一个数组中做缓存。下面是代码修改情况
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
diff --git a/Makefile b/Makefile
index 1c17fe0..0fe144a 100644
--- a/Makefile
+++ b/Makefile
@@ -182,6 +182,7 @@ UPROGS=\
$U/_ls\
$U/_mkdir\
$U/_pingpong\
+ $U/_primes\
$U/_rm\
$U/_sh\
$U/_sleep\
diff --git a/user/primes.c b/user/primes.c
new file mode 100644
index 0000000..d3aa3f6
--- /dev/null
+++ b/user/primes.c
@@ -0,0 +1,56 @@
+#include "kernel/types.h"
+#include "kernel/stat.h"
+#include "user/user.h"
+
+void
+filter(int* pl)
+{
+ int nums[35];
+ int cnt = 0;
+ char buf[1];
+ int pr[2];
+ pipe(pr);
+
+ for (;;) {
+ int r = read(pl[0], buf, sizeof(buf));
+ if (r == 0) break;
+ nums[cnt++] = buf[0];
+ }
+ close(pl[0]);
+
+ if (cnt == 0) return;
+ int first = nums[0];
+ printf("prime %d\n", first);
+
+ for (int i = 0; i < cnt; ++i) {
+ if (nums[i] % first != 0) {
+ buf[0] = nums[i];
+ write(pr[1], buf, sizeof(buf));
+ }
+ }
+ close(pr[1]);
+
+ int pid = fork();
+ if (pid == 0) {
+ filter(pr);
+ }
+}
+
+int
+main(int argc, char *argv[])
+{
+ int p[2];
+ pipe(p);
+
+ for (int i = 2; i < 35; ++i) {
+ char c = i;
+ write(p[1], &c, 1);
+ }
+ close(p[1]);
+
+ filter(p);
+
+ wait(0);
+
+ exit(0);
+}
find
Write a simple version of the UNIX find program: find all the files in a directory tree with a specific name. Your solution should be in the file
user/find.c.
这个任务需要我们实现一个 find 函数。在提示中也指出让我们参考一下 user/ls.c 这个文件。做的过程中没遇到什么问题,就是要把 user/ls.c:26 的 ls 函数搜索文件目录的过程看懂就可以了,下面是这一部分的代码修改:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
diff --git a/Makefile b/Makefile
index 0fe144a..ce27992 100644
--- a/Makefile
+++ b/Makefile
@@ -174,6 +174,7 @@ mkfs/mkfs: mkfs/mkfs.c $K/fs.h $K/param.h
UPROGS=\
$U/_cat\
$U/_echo\
+ $U/_find\
$U/_forktest\
$U/_grep\
$U/_init\
diff --git a/user/find.c b/user/find.c
new file mode 100644
index 0000000..ba1dec2
--- /dev/null
+++ b/user/find.c
@@ -0,0 +1,63 @@
+#include "kernel/types.h"
+#include "kernel/stat.h"
+#include "user/user.h"
+#include "kernel/fs.h"
+
+void
+find(char* dir, char *name)
+{
+ char buf[512], *p;
+ int fd;
+ struct dirent de;
+ struct stat st;
+
+ if ((fd = open(dir, 0)) < 0) {
+ fprintf(2, "find: cannot open %s\n", dir);
+ return;
+ }
+
+ if (fstat(fd, &st) < 0) {
+ fprintf(2, "find: cannot stat %s\n", dir);
+ close(fd);
+ return;
+ }
+ if (st.type != T_DIR) {
+ close(fd);
+ return;
+ }
+ if (strlen(dir) + 1 + DIRSIZ + 1 > sizeof buf) {
+ printf("find: path too long\n");
+ close(fd);
+ return;
+ }
+ strcpy(buf, dir);
+ p = buf + strlen(buf);
+ *p++ = '/';
+
+ while (read(fd, &de, sizeof(de)) == sizeof(de)) {
+ if (de.inum == 0)
+ continue;
+ memmove(p, de.name, DIRSIZ);
+ p[DIRSIZ] = 0;
+ if (strcmp(p, ".") == 0 || strcmp(p, "..") == 0)
+ continue;
+ if (strcmp(p, name) == 0) {
+ printf("%s\n", buf);
+ }
+ find(buf, name);
+ }
+ close(fd);
+}
+
+int
+main(int argc, char *argv[])
+{
+ if (argc != 3) {
+ printf("usage: find dir name\n");
+ exit(1);
+ }
+
+ find(argv[1], argv[2]);
+
+ exit(0);
+}
xargs
Write a simple version of the UNIX xargs program: read lines from the standard input and run a command for each line, supplying the line as arguments to the command. Your solution should be in the file
user/xargs.c.
这个任务让我们实现一个命令 xargs。这个命令以前好像见过,只不过不理解,通过这次实验总算是理解了,阮一峰的博客里有详细的解释。简单来说,在 linux 系统中,有的命令只能在命令行输入参数,比如 echo,用管道的方法无法输出任何内容:
1
echo "Hello" | echo
这里就可以用 xargs 传参:
1
echo "Hello" | xargs echo
还有,xargs 可以进行一些批量操作,比如在当前文件夹下从文件名中带有 dir 的所有文件中查找 hello 这个词:
1
find . dir | xargs grep hello
本次实验中实现的 xargs 的功能与上面的类似,从标准输入中得到一系列的输入,这些输入会以空格或换行分隔,然后将每个分隔后的内容添加到 xargs 后面命令的末尾即可,就是说将按照空格或回车为分界的输入分别添加到 argv 这个字符串数组的后面用 exec 执行即可。本部分代码的修改情况如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
diff --git a/Makefile b/Makefile
index ce27992..7d7f929 100644
--- a/Makefile
+++ b/Makefile
@@ -191,6 +191,7 @@ UPROGS=\
$U/_usertests\
$U/_grind\
$U/_wc\
+ $U/_xargs\
$U/_zombie\
diff --git a/user/xargs.c b/user/xargs.c
new file mode 100644
index 0000000..954e140
--- /dev/null
+++ b/user/xargs.c
@@ -0,0 +1,40 @@
+#include "kernel/types.h"
+#include "kernel/param.h"
+#include "kernel/stat.h"
+#include "user/user.h"
+
+void
+run(int argc, char *argv[], char* left)
+{
+ argv[argc++] = left;
+ argv[argc] = 0;
+ int pid = fork();
+ if (pid == 0) {
+ exec(argv[1], argv + 1);
+ }
+ wait(0);
+}
+
+int
+main(int argc, char *argv[])
+{
+ char buf[100];
+ int r;
+ int len = 0;
+
+ while ((r = read(0, buf + len, sizeof(buf + len))) != 0) {
+ len += r;
+ }
+ buf[len] = 0;
+
+ char *p = buf;
+ for (int i = 0; i < len; ++i) {
+ if (buf[i] == '\n' || buf[i] == ' ') {
+ buf[i] = 0;
+ run(argc, argv, p);
+ p = buf + i + 1;
+ }
+ }
+
+ exit(0);
+}