Paper | MaskFormer 系列论文
Paper | MaskFormer 系列论文
MaskFormer
三种不同分割任务
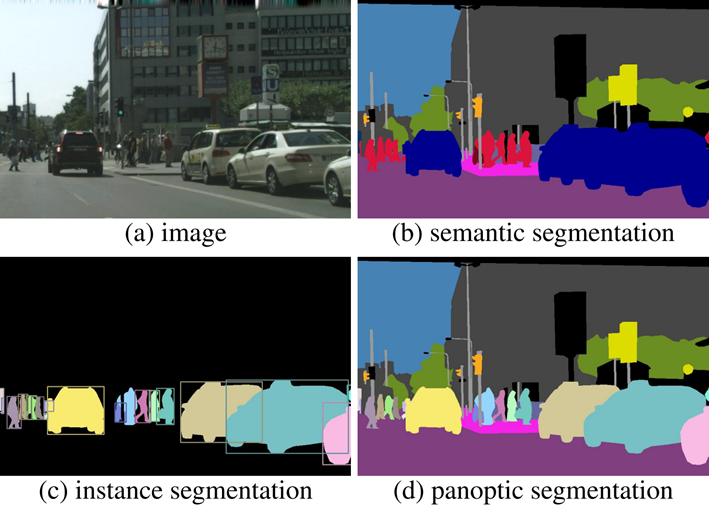
- Semantic Segmentation:对一张图片的所有像素点进行分类
- Instance Segmentation:目标检测和语义分割的结合
- Panoptic Segmentation:语义分割和实例分割的结合
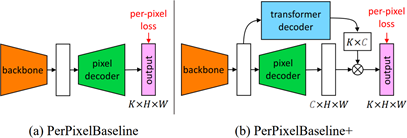
Per-pixel classification formulation
语义分割的目的是将图像划分为具有不同语义类别的区域,自 FCN 出现以后,语义分割问题就被视为像素分类的任务来解决,将其从一个分割问题转变为分类问题
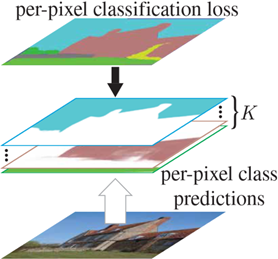
数学描述:预测 $H\times W$ 图像中的每个像素在所有可能 $K$ 类的概率分布:
\[y=\{p_i|p_i\in\Delta^K\}_{i=1}^{H\cdot W}\]像素的标签
\[y^{gt}=\{y_i^{gt}|y_i^{gt}\in\{1,\dots,K\}\}_{i=1}^{H\cdot W}\]Per-pixel cross-entropy loss:
\[\mathcal L_\text{pixel-cls}(y,y^{gt})=\sum_{i=1}^{H\cdot W}-\log{p_i(y_i^{gt})}\]
几个问题:
- 语义分割为什么常用 per-pixel classification
- Mask classification 在分割任务中常与 box 结合,比较复杂,限制了其在语义分割中的应用
- 实例分割的常用方法:
- Mask classification box-based:Mask R-CNN、DETR 等
- Mask R-CNN 同时利用目标检测和语义分割的结果,通过目标检测提供的目标最高置信度类别的索引,将语义分割中目标对应的 mask 进行抽取
- 实例分割为什么不用 pixel classification
- Pixel classification 输出的预测数量是固定的,不能返回 instance 任务所需的动态可变数量的预测
Key observation
mask classification 足够通用,可以使用完全相同的模型、损失和训练过程以统一的方式解决语义和实例分割任务。由此自然地引出了两个问题:
- 单个掩码分类模型能否简化语义和实例分割任务?
- 这种掩码方法能否优于现有的逐像素分类方法?
Contribution
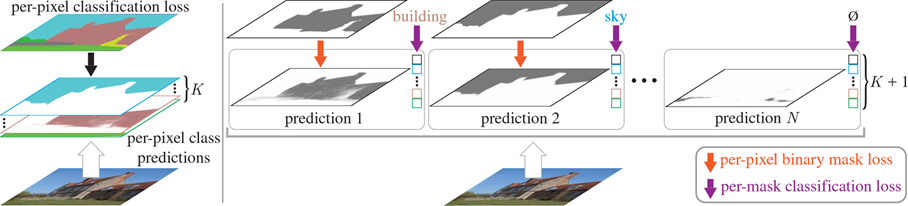
提出了 MaskFormer,可以将现有的逐像素分类模型转变为掩码分类
Mask classification formulation
掩码分类将分割任务分为两个步骤:
- 将图像划分为 $N$ 个区域($N$ 不需要等于 $K$),并用二进制掩码表示:
将每个区域作为一个整体与 $K$ 个类别上的某种分布相关联,将输出 $z$ 定义为 $N$ 个概率掩码对: $\{m_i|m_i\in[0,1]^{H\times W}\}_{i=1}^N$
- 这里类别概率 $p_i\in\Delta^{K+1}$ 包含“无对象”类别($\Phi$),因为区域数 $N$ 不需要等于类别数 $K$,所以一个类别可以有多个不同的掩码预测,使得 mask classification 适用于语义分割和实例分割
预测结果
- ground-truth 标签为: $z^{gt}=\{(c_i^{gt},m_i^{gt})|c_i^{gt}\in{1,\dots,K},m_i^{gt}\in\{0,1\}^{H\times W}\}$ ,其中 $c_i^{gt}$ 是第 $i$ 个 mask 的真实类别
- 预测的区域数量 $N$ 一般会大于标签中的区域块 $N^{gt}$,为了可以一对一匹配,借鉴 DETR,对 ground-truth 添加 no object tokens 使得两者数量相等
借鉴 DETR,使用基于匈牙利算法的二值匹配算法(bipartite matching)将标签和预测结果的不同区域(class 和 mask)进行匹配:
\[-p_i(c_j^{gt})+\mathcal{L}_\text{mask}(m_i,m_j^{gt})\]最后的损失函数为:
\[\mathcal L_\text{mask-cls}(z,z^{gt})=\sum_{j=1}^N[-\log{p_{\alpha(j)}(c_j^gt)}+\mathcal 1_{c_j^{gt}\neq\phi}\mathcal L_\text{mask}(m_{\alpha(j)}m_j^{gt})]\]模型结构
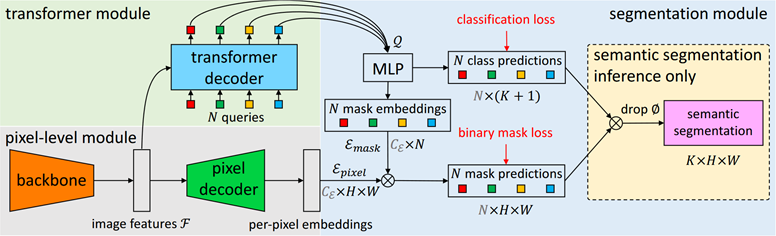
- Pixel-level module
- 提取 pixel-level embeddings:$\varepsilon_\text{pixel}\in\mathbb{R}^{C_\mathcal{Q}\times H\times W}$
- Backbone 可使用 ResNet 或 Swin-Transformer
- Pixel decoder 使用基于 FPN 的结构
- Transformer module
- 参考 DETR,使用标准 Transformer decoder 将 image feature 和 $N$ 个 object queries 作为输入,输出 $N$ 个 per-segment embeddings:$\mathcal{Q}=\mathbb{R}^{C_\mathcal{Q}\times N}$
- Segmentation module
- 用 N 个 per-segment embeddings Q 分别生成 N 个 class predictions 和 N 个 mask embeddings
- Class predictions:使用线性分类器和 softmax 输出类别,得到类别概率 $\{p_i\in\Delta^{K+1}\}_{i=1}^N$
Mask predictions:用 mask embeddings 点乘 pixel embeddings,通过 sigmoid 得到 N 个 binary mask 预测
\[m_i[h,w]=\text{sigmoid}(\varepsilon_\text{mask}[:,i]^T\cdot\varepsilon_\text{pixel}[:,h,w])\]
Mask-classification inference
提出两种推理步骤(推理策略的具体选择很大程度上取决于评估指标而不是任务)
- General inference
- 针对全景和语义分割。通过 $argmax_{i:c_i\neq\phi}p_i(c_i)\cdot m_i[h,w]$ 将每个像素 $[h,w]$ 分配给 $N$ 个预测概率掩码对之一:
- 对于 $N$ 个区域,每个区域有 $K+1$ 个类别概率,首先确定每个区域中最大概率的类别 $c_i$
- 当前像素点 $[h,w]$ 同样具有属于每个区域的概率,即 $m_i$
- 将两者结合即可得到当前像素点所属的 mask 编号 $i$ 以及对应的类别 $c_i$
- 对于语义分割,相同类别标签的 mask 被合并;对于实例分割,概率掩码对的索引 $i$ 可以区分同一类的不同实例
- 针对全景和语义分割。通过 $argmax_{i:c_i\neq\phi}p_i(c_i)\cdot m_i[h,w]$ 将每个像素 $[h,w]$ 分配给 $N$ 个预测概率掩码对之一:
- Semantic inference
- 针对语义分割。使用 $argmax_{c\in\{1,\dots,K\}}\sum_{i=1}^Np_i(c)\cdot m_i[h,w]$ 对类别进行推测
- 实验发现针对语义分割直接关注 per-pixel class probability $\sum_{i=1}^Np_i(c)\cdot m_i[h,w]$ 能够产生更好的结果
- $p$ 表示 $K$ 个类别(不包括 $\Phi$),每个类别有长度为 $N$ 的类别特征
- $m$ 表示每个像素点有长度为 $N$ 的维度特征
- 将 $m$ 与 $p$ 进行点积,取其中最大值所在的类别作为最终的类别 $c$
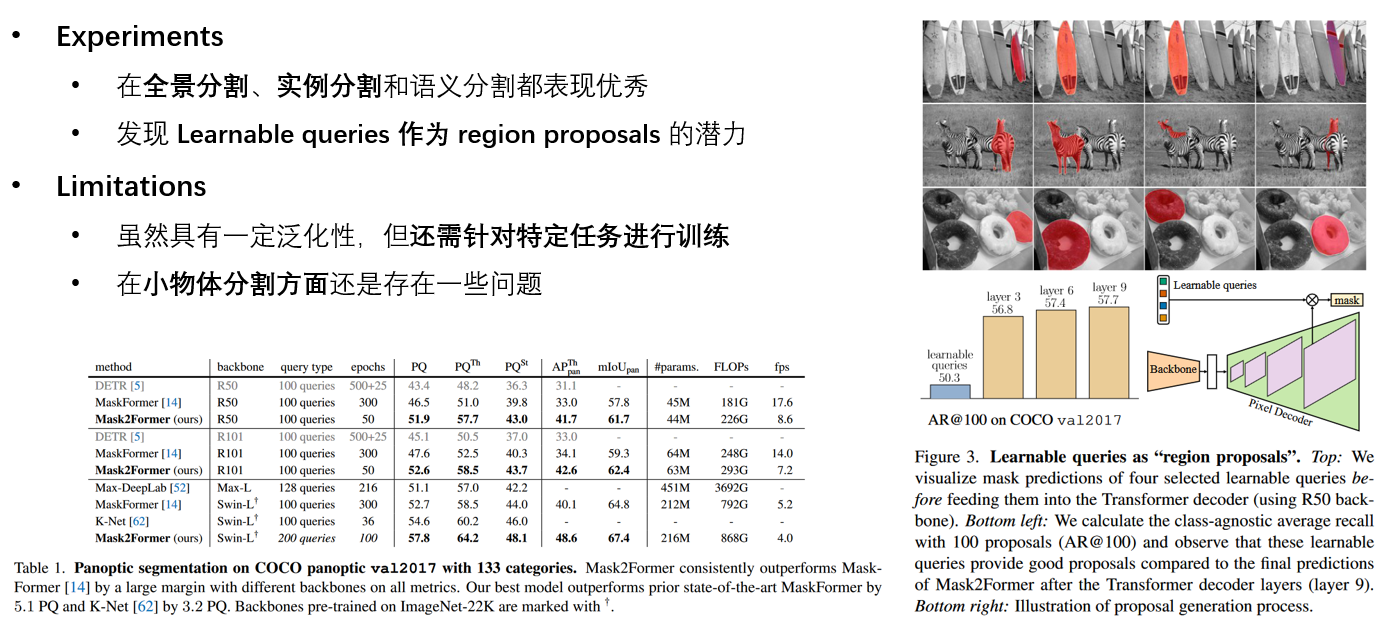
Experiments
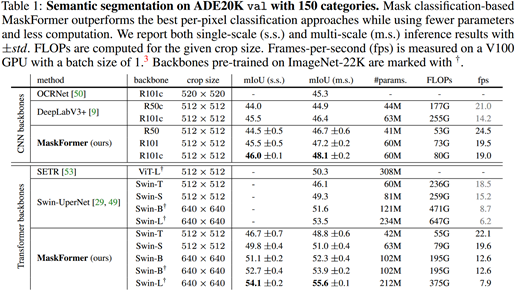
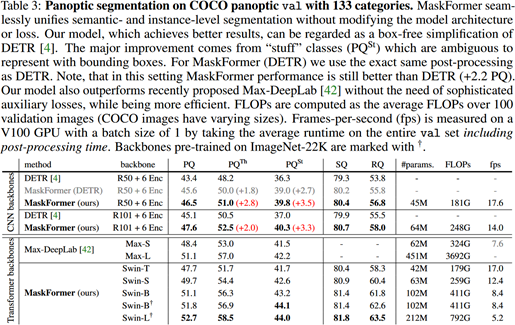
Ablation studies

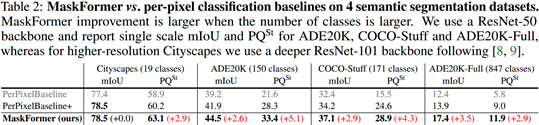
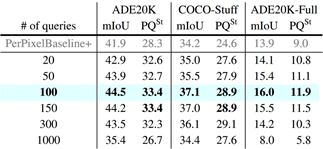
- MaskFormer 优于 per-pixel classification baselines
- 类别越多 mask classification 模型的提升越大
- Object queries 的数量在 100 时表现最佳
- 每个 query 都能捕获多个类别的掩码
Discussion: Compare with DETR
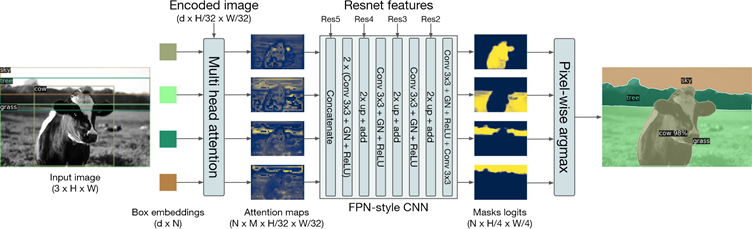
MaskFormer 可被视为 DETR 的“无盒”版本
- 直接进行 mask prediction,无需 box,实现更精准的预测
- 减少计算量。在 MaskFormer 中,通过上采样得到高分辨率的 pixel embeddings 是共享的,而 DETR 进行全景分割时,对 N 个 box embeddings 分别生成了 N 个低分辨率的 attention map 再进行上采样
Mask2Former
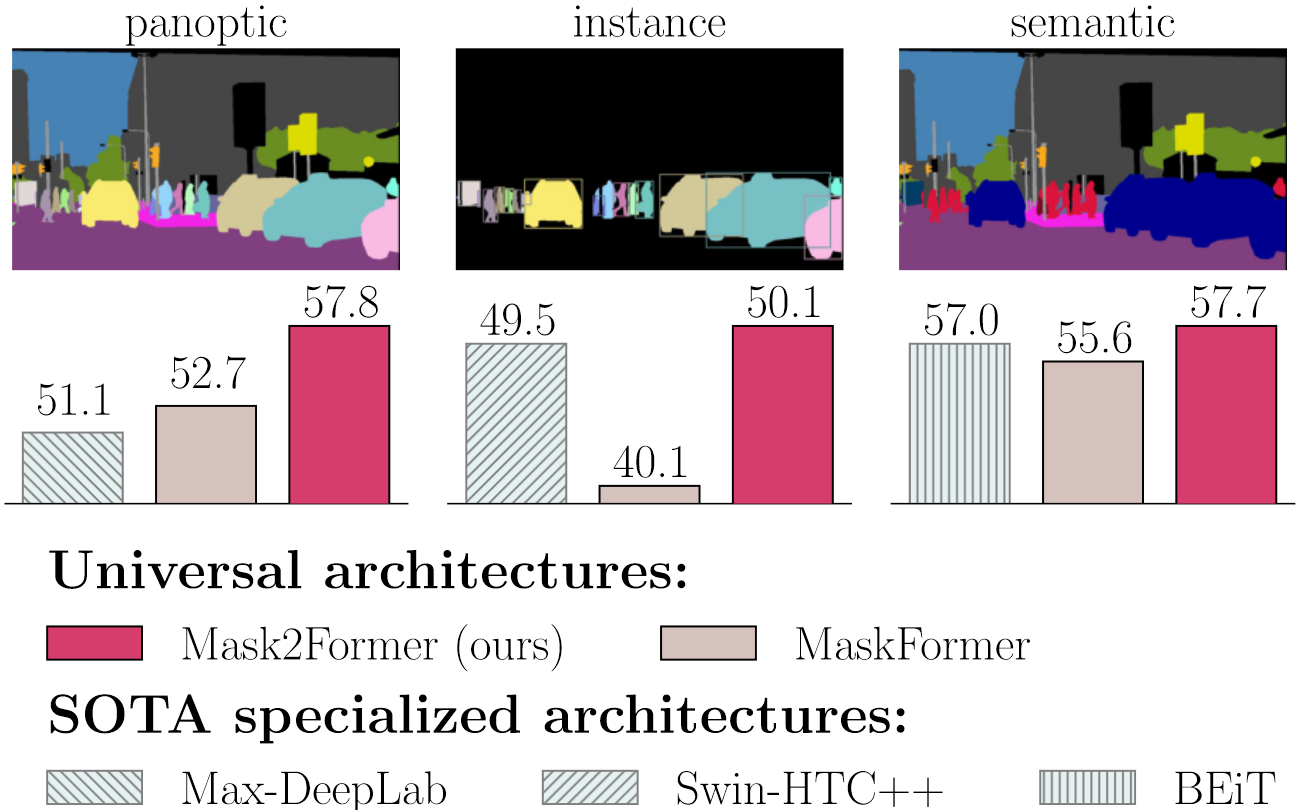
MaskFormer 的问题
- 在实例分割中与最好的方法还有差距(如左图)
- 难以训练,基于 DETR 的结构,训练一张图像就需要 18 GB 显存
由此引出 Mask2Former

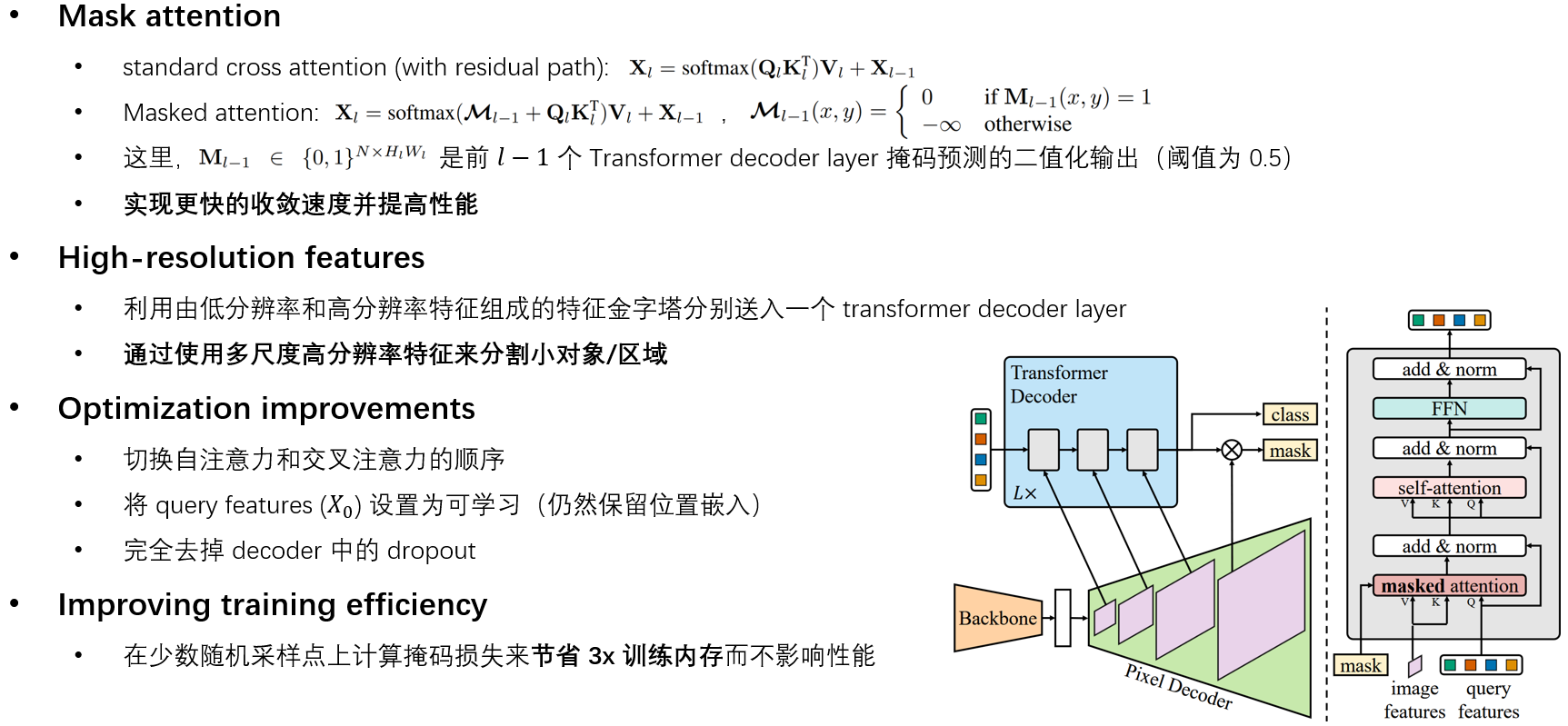
Mask2FormerVIS

本文由作者按照 CC BY 4.0 进行授权