CMU 15-445 | Project #3 - Query Execution
这个实验相对于 Project2 来说主要是量大,需要摸清 AbstractExecutor 与 AbstractPlanNode 的执行流程。首先祭上整个项目的结构图:
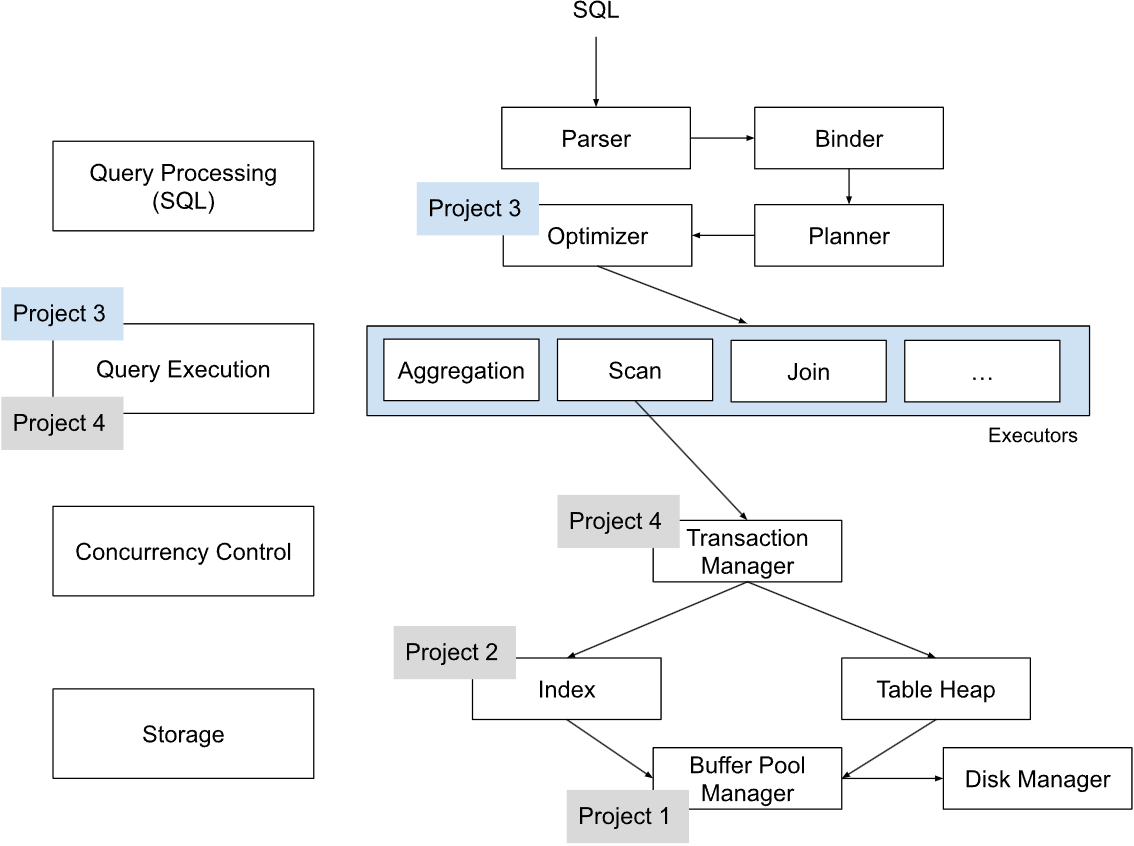
可以看到,当一个 SQL 语句被送入 Bustub 后,会分别经过 Parser、Binder、Optimizer、Executor 四个阶段。其中 Executor 阶段又包含多种 Executor,如 SeqScanExecutor、IndexScanExecutor、HashJoinExecutor 等。这些 Executor 会根据 SQL 语句的不同部分,分别执行不同的操作。下面直接看代码中这些步骤是怎么联系起来的,为了方便展示,只给出主要步骤
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
auto BustubInstance::ExecuteSqlTxn(const std::string &sql,
ResultWriter &writer, ...) {
// 解析是否为 `\\dt`, `\\di`, `\\help` 等命令
bustub::Binder binder(*catalog_);
binder.ParseAndSave(sql);
for (auto *stmt : binder.statement_nodes_) {
auto statement = binder.BindStatement(stmt);
bool is_delete = false;
switch (statement->type_) {
case StatementType::CREATE_STATEMENT: {
const auto &create_stmt = dynamic_cast<const CreateStatement &>(*statement);
HandleCreateStatement(txn, create_stmt, writer);
continue;
}
// 处理 INDEX, SHOW, SET, EXPLAIN, TRANSACTION 等 STATEMENT
}
// Plan the query.
bustub::Planner planner(*catalog_);
planner.PlanQuery(*statement);
bustub::Optimizer optimizer(*catalog_, IsForceStarterRule());
auto optimized_plan = optimizer.Optimize(planner.plan_);
auto exec_ctx = MakeExecutorContext(txn, is_delete);
std::vector<Tuple> result_set{};
is_successful
&= execution_engine_->Execute(optimized_plan, &result_set, txn, exec_ctx.get());
// Return the result set as a vector of string.
auto schema = planner.plan_->OutputSchema();
for (const auto &column : schema.GetColumns()) {
writer.WriteHeaderCell(column.GetName());
}
// Transforming result set into strings.
for (const auto &tuple : result_set) {
for (uint32_t i = 0; i < schema.GetColumnCount(); i++) {
writer.WriteCell(tuple.GetValue(&schema, i).ToString());
}
}
}
return is_successful;
}
可以看到,整个执行流程是这样的:
- 解析 SQL 语句,生成
Statement对象 - 绑定
Statement对象,生成AbstractPlanNode对象 - 优化
AbstractPlanNode对象,生成优化后的AbstractPlanNode对象 - 执行
AbstractPlanNode对象,生成结果集 - 将结果集转换为字符串,输出
下面我们对一些细节进行讨论
什么是 Statement?
Statement 是一个抽象类,它有很多派生类,如 CreateStatement、DropStatement、InsertStatement、SelectStatement 等。每个 Statement 对象都有一个 type_ 属性,用于标识这个 Statement 的类型。在 Binder 阶段,会根据 SQL 语句的不同部分生成不同的 Statement 对象
在 Bustub 中,BoundStatement 是一个非常关键的组件,主要用于表示带有参数的 SQL 查询,它负责将 SQL 查询模板与实际的参数值绑定在一起。BoundStatement 提供了一种方式,使得 SQL 查询可以安全地处理输入,防止 SQL 注入攻击,并且支持查询优化,通过预编译和缓存查询计划来提高性能
Planner 做了什么?
Planner 的主要工作是将 Statement 对象转换为 AbstractPlanNode 对象。AbstractPlanNode 是一个抽象类,它有很多派生类,如 SeqScanPlanNode、IndexScanPlanNode、HashJoinPlanNode 等。每个 AbstractPlanNode 对象都有一个 type_ 属性,用于标识这个 AbstractPlanNode 的类型。在 Planner 阶段,会根据 Statement 对象的不同部分生成不同的 AbstractPlanNode 对象
Bustub 目前支持 Plan 的 Statement 有 Select、Insert、Delete 和 Update,下面举个 PlanInsert 的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
auto Planner::PlanInsert(const InsertStatement &statement) -> AbstractPlanNodeRef {
auto select = PlanSelect(*statement.select_);
const auto &table_schema = statement.table_->schema_.GetColumns();
const auto &child_schema = select->OutputSchema().GetColumns();
if (!std::equal(table_schema.cbegin(), table_schema.cend(), child_schema.cbegin(),
child_schema.cend(), [](auto &&col1, auto &&col2) {
return col1.GetType() == col2.GetType();
})) {
throw bustub::Exception("table schema mismatch");
}
auto insert_schema = std::make_shared<Schema>(
std::vector{Column("__bustub_internal.insert_rows", TypeId::INTEGER)});
return std::make_shared<InsertPlanNode>(std::move(insert_schema),
std::move(select), statement.table_->oid_);
}
Planner 最终得到的是一个 AbstractPlanNode 对象,接下来就到了优化的阶段
如何进行 Optimize?
Optimizer 的主要工作是对 AbstractPlanNode 对象进行优化,生成优化后的 AbstractPlanNode 对象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
auto Optimizer::Optimize(const AbstractPlanNodeRef &plan) -> AbstractPlanNodeRef {
if (force_starter_rule_) {
// Use starter rules when `force_starter_rule_` is set to true.
auto p = plan;
p = OptimizeMergeProjection(p);
p = OptimizeMergeFilterNLJ(p);
p = OptimizeOrderByAsIndexScan(p);
p = OptimizeSortLimitAsTopN(p);
p = OptimizeMergeFilterScan(p);
p = OptimizeSeqScanAsIndexScan(p);
return p;
}
// By default, use user-defined rules.
return OptimizeCustom(plan);
}
为啥需要 Optimizer 呢?因为根据 SQL 直接得到的 Plan 可能并不是最优的,我们需要将其转为更高效的方式。比如,OptimizeMergeProjection 就是将 Project 和 Filter 合并,减少了一次扫描;OptimizeOrderByAsIndexScan 就是将 OrderBy 转为 IndexScan,减少了排序的开销;OptimizeSortLimitAsTopN 就是将 Sort 和 Limit 合并,减少了排序的开销。这一步是非常重要的,因为它直接影响到了查询的性能,最终输出的是一个优化后的 AbstractPlanNode 对象
Executor 启动
经过上述步骤,我们得到了一个优化后的 AbstractPlanNode 对象,接下来就是执行这个 Plan 了。Executor 的主要工作是执行 AbstractPlanNode 对象,生成结果集:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
auto Execute(const AbstractPlanNodeRef &plan,
std::vector<Tuple> *result_set,
Transaction *txn,
ExecutorContext *exec_ctx) -> bool {
BUSTUB_ASSERT((txn == exec_ctx->GetTransaction()), "Broken Invariant");
// Construct the executor for the abstract plan node
auto executor = ExecutorFactory::CreateExecutor(exec_ctx, plan);
// Initialize the executor
auto executor_succeeded = true;
try {
executor->Init();
PollExecutor(executor.get(), plan, result_set);
PerformChecks(exec_ctx);
} catch (const ExecutionException &ex) {
// ...
}
return executor_succeeded;
}
针对不同的 AbstractPlanNode,首先得到不同的 Executor,然后就是 正式 执行这个 Plan 了。对于每个 Executor,都有一个 Init 方法,用于初始化这个 Executor,然后就是 PollExecutor 方法,用于执行这个 Executor,最终得到结果集:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
class AbstractExecutor {
public:
explicit AbstractExecutor(ExecutorContext *exec_ctx) : exec_ctx_{exec_ctx} {}
virtual void Init() = 0;
virtual auto Next(Tuple *tuple, RID *rid) -> bool = 0;
virtual auto GetOutputSchema() const -> const Schema & = 0;
auto GetExecutorContext() -> ExecutorContext * { return exec_ctx_; }
protected:
ExecutorContext *exec_ctx_;
};
需要注意,Executor 的输出结果是在 Next 方法中得到的,每次调用 Next 方法,都会得到一个 Tuple 对象,直到 Next 返回 false 为止。这样,我们就得到了一个完整的执行流程