Paper | Advancing Referring Expression Segmentation Beyond Single Image
TL;DR
本文提出了一种名为群组式引用表达分割(GRES)的新方法,以解决引用表达分割(RES)在现实世界场景中的限制。RES专注于根据文本描述在单个图像中分割对象,但无法保证描述的对象在图像中的存在。GRES将RES扩展到一组相关图像,并提出了一种名为群组引用分割器(GRSer)的基线方法,利用语言和组内视觉连接来获得更好的结果。该论文还介绍了群组引用数据集(GRD),确保在群组中的所有图像中对描述的对象进行了完整的注释。实验结果表明,GRSer在GRES、RES和Co-SOD任务中实现了最先进的性能
1. Introduction

引用表达分割(Referring Expression Segmentation,RES)的目的是根据文本的描述寻找给定图像中的目标物体,并生成一个相应的分割掩码。这个方向已经产出了很多方法和数据集。尽管如此,RES 的设定过于理想,它是将由文本描述的单个图像中已知存在的内容进行分割。这限制了在现实世界中应用 RES 的实用性,因为我们并不总是能够确定描述的对象是否存在于特定的图像中。通常,在一组图像中,其中可能只有一些图像包含所描述的对象。为了解决这个问题,本文引入了一个新的现实场景,即群组式引用表达分割(Group-wise Referring Expression Segmentation,GRES),并将其定义为从一组相关图像中分割语言表达描述的对象的过程。文章在两个方面建立了 GRES 的基础:
- 实现了一个名为群组引用分割器(Grouped Referring Segmenter, GRSer)的基线方法,该方法明确利用语言和组内视觉联系来得到结果
- 构建了群组引用数据集(Group Referring Dataset,GRD),该数据集确保在群组中的所有图像中对描述的对象都进行了完整的注释
2. Related Work
3. Proposed Method
本文提出的方法是 Grouped Referring Segmenter(GRSer)。给定一个指定对象的文本描述,GRSer 会同时处理一组相关图像,然后输出目标对象的所有相应像素级掩码。特别地,对于负样本(即没有目标对象的图像),其输出掩码是 0。GRSer 的结构如下:
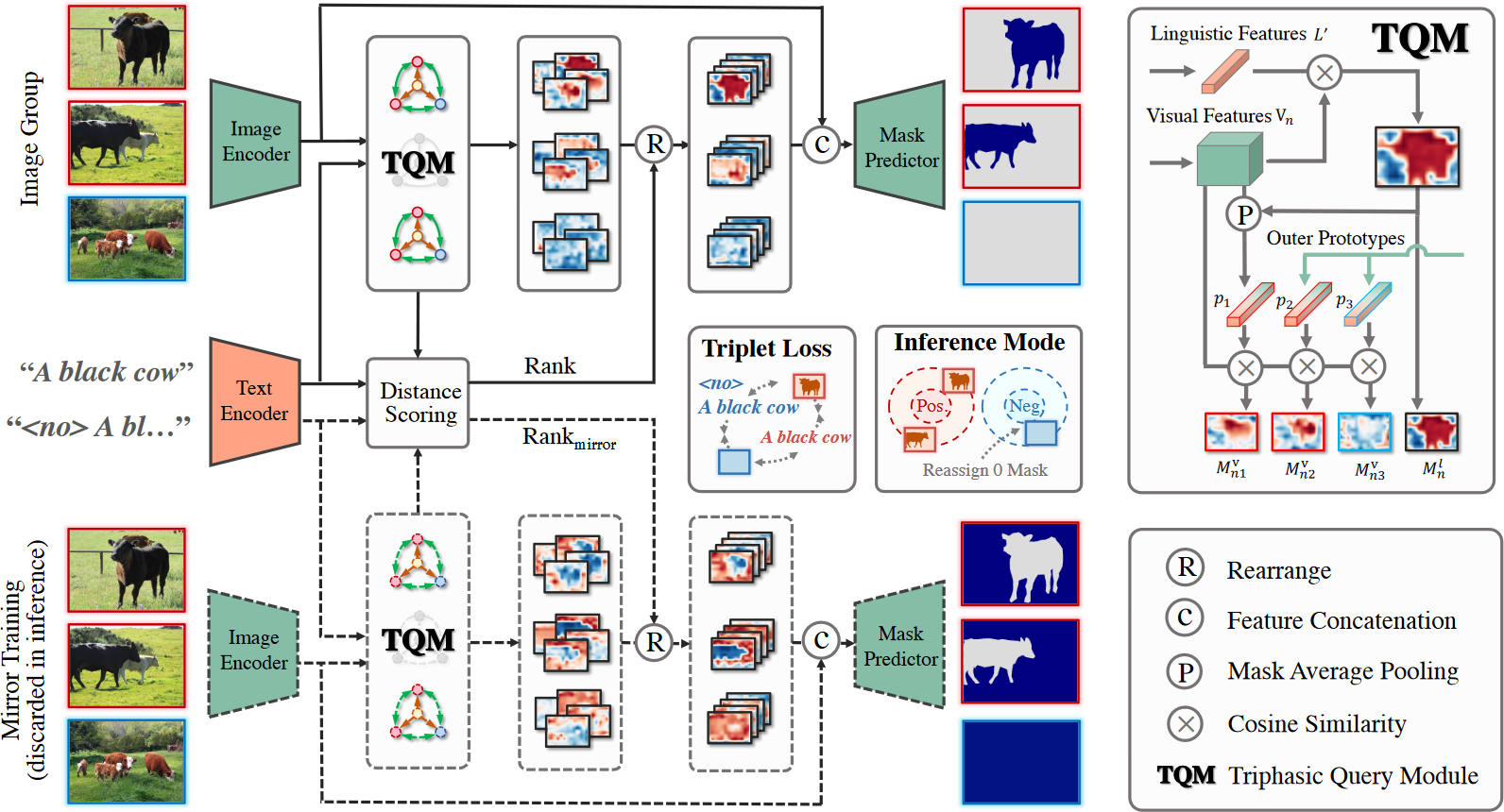
本方法由如下几个模块组组成:
- Text & Image Encoder:使用 BERT 提取文本特征 $\mathbf{L}\in\mathbb{R}^{C_l}$,这里 $C_l$ 是文本特征的通道数;同时,文章通过在文本前添加前缀
<no>来构建一个相反的表达,其文本特征为 $\mathbf{L}^{anti}\in\mathbb{R}^{C_l}$。使用 LAVT 的方法为一组中的每一张照片 $x_n$ 提取视觉特征 $\mathbf{V}_n\in\mathbb{R}^{C_v\times H\times W}$ - TQM & Heatmap Hierarchizer:TQM 用于捕获语言-视觉和组内的视觉-视觉语义关系,用于生成热图,反映语言和组内视觉特征之间的空间关系。这些热图在 Heatmap Hierarchizer 中根据他们和文本表示的重要性进行排序和重新排列,从而更好地激活他们用于掩码预测的定位能力
- Mask Predictor:排序完成后的热图与视觉特征 $\mathbf{V}_n$ 连接以获得三相特征 $\mathbf{z}_n$,该特征集成了 TQM 和 Heatmap Hierarchizer 中目标对象的判别线索。$\mathbf{z}_n$ 用于区分正样本和负样本,并预测分割掩码。在推理过程中,会计算正距离 $d^{pos}=d(\mathbf{z}_n,\mathbf{L})$ 和负距离 $d^{neg}=d(\mathbf{z}_n,\mathbf{L}^{anti})$,其中 $d(\cdot)$ 为欧几里得距离。如果 $d^{pos}+m<d^{neg}$($m$ 是 margin 值),则图像 $x_n$ 被识别为正样本,然后将其 $z_n$ 传输到解码器以输出分割掩码。如果不是,则将 $0$ 掩码重新分配为负输出
3.1 Triphasic Query Module (TQM)
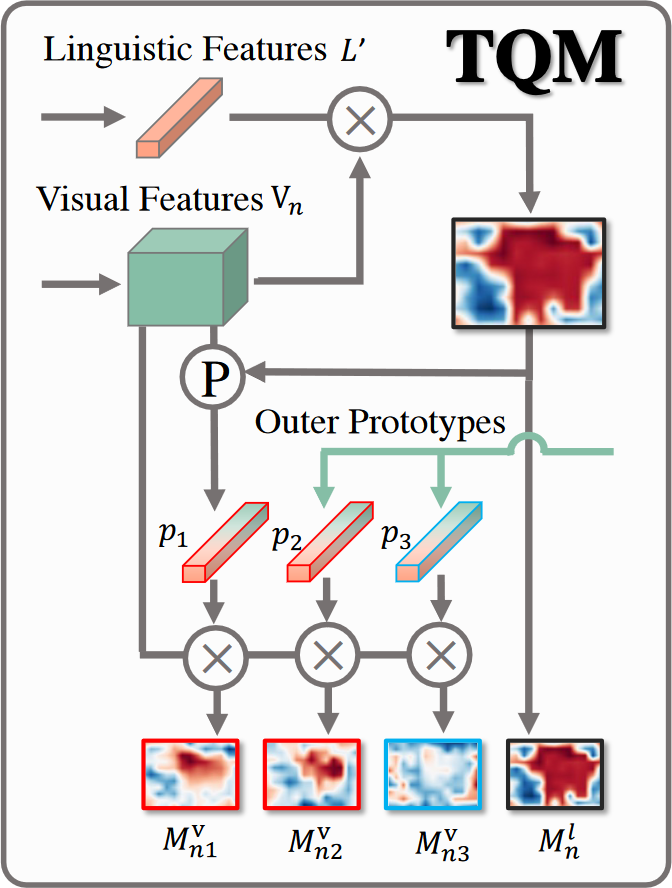
由于固有的模态差距,通过语言特征直接查询对象通常会导致很粗糙的语言激活热图。本文利用组内同模态视觉特征来充当“专家”,从他们的角度提供建议的热图。为此,设计了 TQM,其中 Triphasic 意味着目标对象不仅通过语言特征进行查询,还通过组内同模态视觉特征进行查询
首先,为了检测响应引用表达的视觉特征图中最具辨别力的区域,生成语言激活热图 $\mathbf{M}_n^l\in\mathbb{R}^{H\times W}$。详细点说,计算展平的视觉特征 $\mathbf{V}_n\in\mathbf{R}^{C_v\times HW}$ 和语言特征 $\mathbf{L}’=\omega_l(\mathbf{L})\in\mathbb{R}^{C_v}$ 之间的余弦相似度,这里 $\omega_l$ 是用于对齐多模态特征的一个 $1\times1$ 卷积
\[\mathbf{M}_n^l=\frac{\mathbf{V}_n^T\cdot\mathbf{L}'}{\lVert\mathbf{V}_n\rVert\lVert\mathbf{L}'\rVert}\]其次,$\mathbf{M}_n^l$ 与视觉特征 $\mathbf{V}_n$ 逐元素相乘,并用 mask average pooling 对输出特征沿空间维度(即 $H\times W$)进行平均,生成对应于图片 $x_n$ 的原型 $\mathbf{p}_n\in\mathbb{R}^{C_v}$,即
\[\mathbf{p}_n=avg(\mathbf{M}_n^l\odot\mathbf{V}_n)\]其中 $\mathbf{M}_n^l$ 被广播到与 $\mathbf{V}_n$ 相同的大小
接下来,在当前图片 $x_n$ 和一组原型之间进行组内查询,这些原型作为“专家”从它们的角度提供本地化的热图建议。详细来说,将展平的视觉特征 $\mathbf{V}n$ 与 ${\mathbf{p}_i}{i=1}^N$ 中的每个原型 $\mathbf{p}i$ 逐一计算余弦相似度,然后生成 $N$ 个视觉激活热图 $\mathbf{M}_n^v={\mathbf{M}{ni}^v}_{i=1}^N$,即
\[\mathbf{M}_{ni}^l=\frac{\mathbf{V}_n^T\cdot\mathbf{p}_i}{\lVert\mathbf{V}_n\rVert\lVert\mathbf{p}_i\rVert}\]其中 $n$ 表示图像在组中的索引,$i$ 表示原型在组中的索引。从图中可以看出,这四个 $\mathbf{M}_{ni}^v$ 比 $\mathbf{M}_n^l$ 表现出更强的定位能力,从而为掩模预测提供更准确的指导
3.2 Heatmap Hierarchizer
由 TQM 的“专家”建议的视觉激活热图可能不够均匀,尤其是存在负样本的时候。为了解决这个问题,本文提出了一个热图分层器,根据置信度评估策略对这些视觉激活热图进行排序和重新排列
为了获得不同热图的排名,文章定义了基于多模态表示距离的评分标准。详细来说,计算组 ${\mathbf{p}i}{i=1}^N$ 中的每个原型与语言特征 $\mathbf{L}$ 之间的欧几里得距离,以获得正分数 ${s_i^{pos}}{i=1}^N$,负分数 ${s_i^{neg}}{i=1}^N$ 通过类似的方式求得。这样,$s_i^{pos}$ 越小,说明原型 $\mathbf{p}i$ 越接近目标对象,意味着其对应生成的热图 $\mathbf{M}{ni}^v$ 越可靠。根据对应的 $s_i^{pos}$(从小到大)和 $s_i^{neg}$(从大到小),可以得到 $N$ 张视觉激活热图 $\mathbf{M}n^v={\mathbf{M}{ni}^v}_{i=1}^N$ 的正排序 $R^{pos}$ 和负排序 $R^{neg}$。正排序和负排序求和得到最后的排序
\[\overline{\mathbf{M}}_n^v=\text{rearrange}(\mathbf{M}_n^v|R^{pos}+R^{neg})\]这里 rearrange 表示更改这些堆叠热图的通道顺序。接下来将这些热图与视觉特征 $\mathbf{V}_n$ 连接起来得到用于掩膜预测的三相特征 $\mathbf{z}_n$
3.3 Training Objectives
- Training with Negative Samples
- Triplet Margin Loss:三元组边缘损失的目标是使锚点和正例更紧密地结合在一起,同时将锚点从负例中拉开
- Mirror Training Strategy:为了进一步迫使模型理解语言反特征 $\mathbf{L}^{anti}$ 中包含的语义,还设计了一种镜像训练策略。直观上,语言反特征代表给定表达的相反语义,因此文章明确地将语言反特征与图像背景(即图像中目标对象的外部)相关联
4. Proposed Dataset

4.1 Dataset Highlights
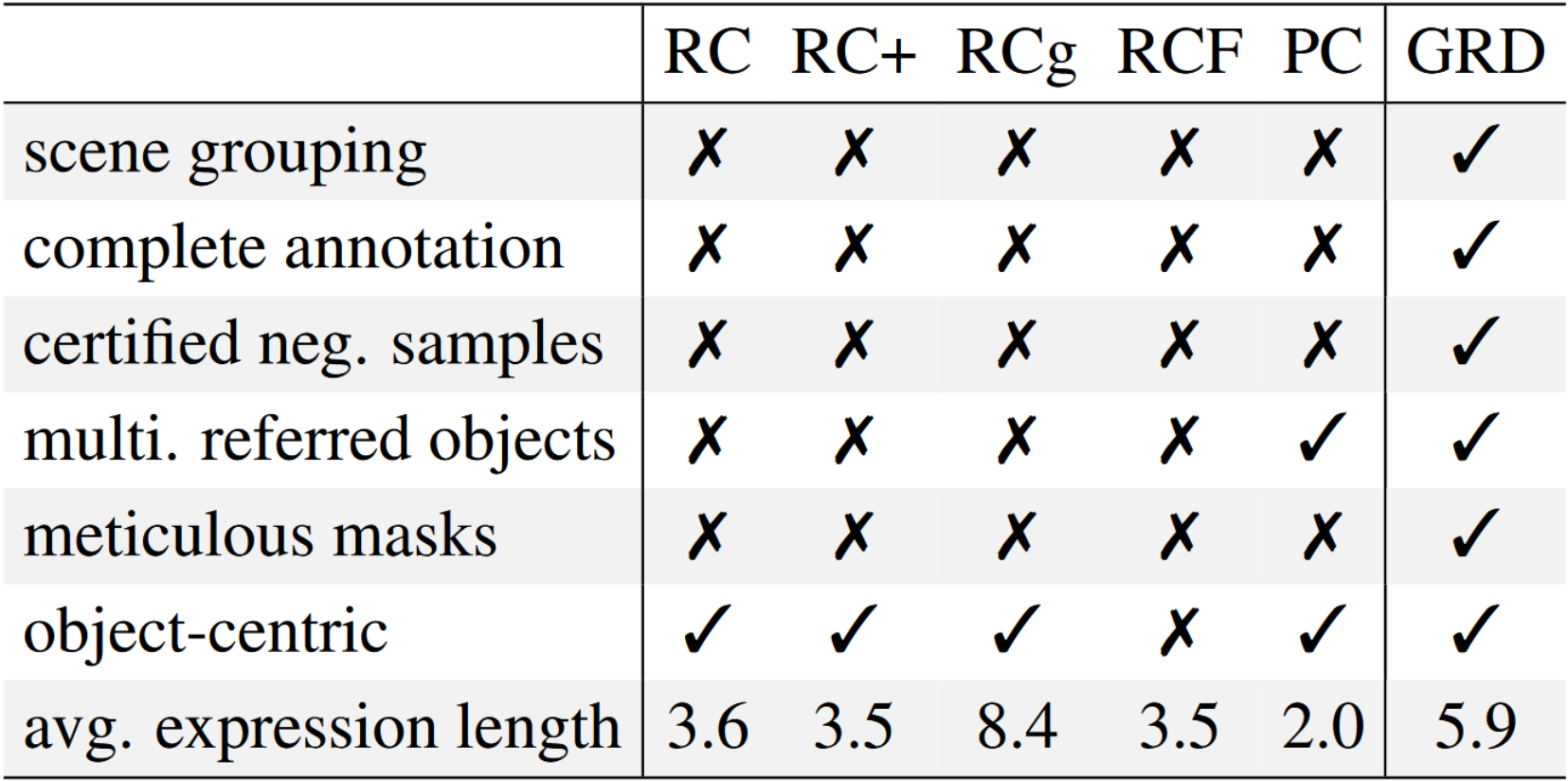
在收集的所有图片中,对于给定的文本表达,文章在所有图片中标记了所有被描述的对象,没有遗漏。这是 GRD 与同类数据集最基本的区别。除了完整的注释以外,还有一些地方使 GRD 与众不同:
- GRD 每组中的图像都是相关的,因此即使所描述的目标没有出现在该组中的某些图像上,这些图像中的场景往往与描述接近,这使得这个数据集更具挑战性
- GRD 中的精细注释能够与当前 RES 数据集相比客观评估模型性能
由于这些功能,GRD 可以帮助许多其他视觉语言任务,例如视觉接地(visual grounding)、RES 和接地字幕(grounding caption)。GRD 可免费用于非商业研究
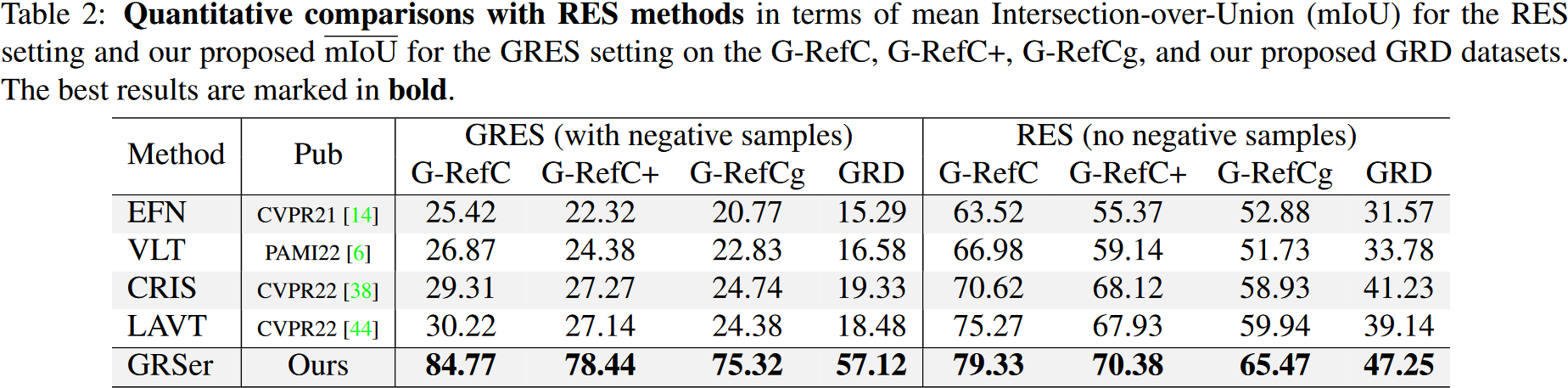
5. Experiments
6. Conclusion
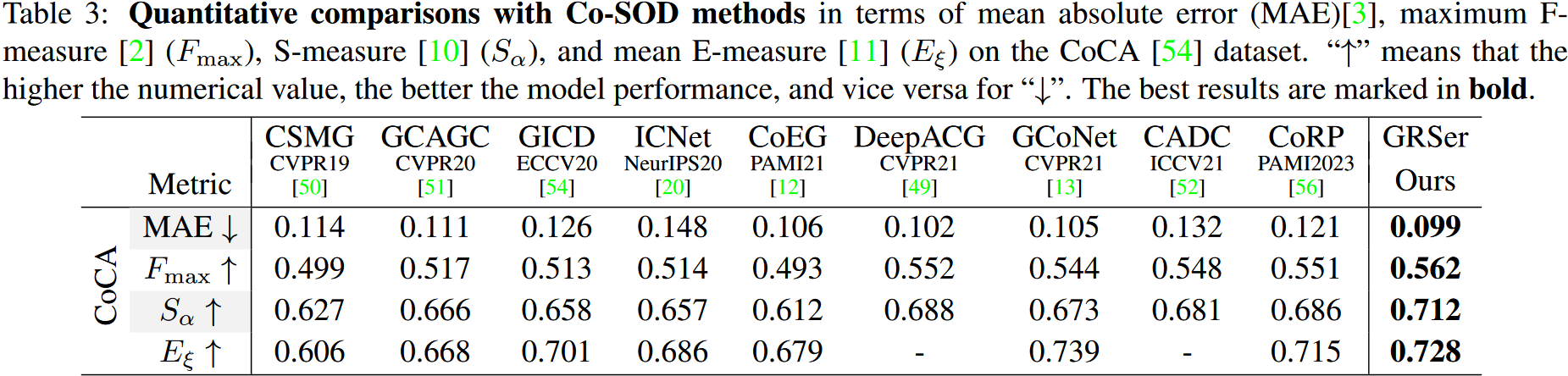
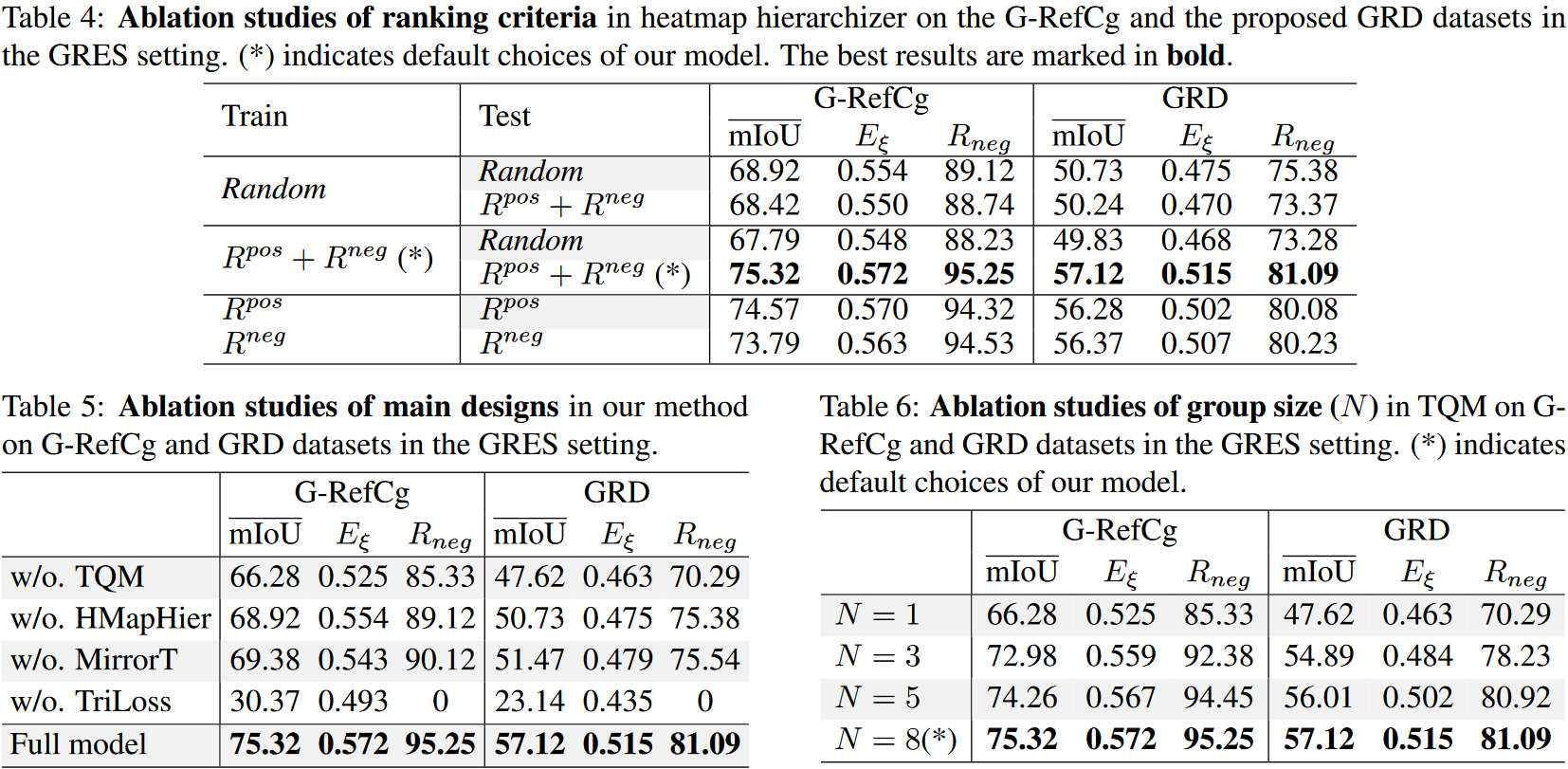
本文提出了一种名为分组引用表达分割(GRES)的现实多模态设置,它放宽了 RES 中理想化设置的限制,将其扩展到相关图像的集合。为了实现这种新设置,文章提出了一个名为 GRD 的具有挑战性的数据集,它通过以分组方式收集图像并彻底注释正样本和负样本来有效地模拟现实世界的场景。此外,还提出了一种新颖的基线方法 GRSer 来显式捕获语言-视觉和视觉-视觉特征交互,以更好地理解目标对象。大量实验表明,本文的方法在 GRES、RES 和 Co-SOD 上实现了 SOTA 性能